
On New Year’s Eve 2018, I published an article which instructed how to scrape pages of a site and write the results into Google BigQuery. I considered it to be a cool way to build your own web scraper, as it utilized the power and scale of the Google Cloud platform combined with the flexibility of a headless crawler built on top of Puppeteer.
In today’s article, I’m revisiting this solution in order to share with you its latest version, which includes a feature that you might find extremely useful when auditing the cookies that are dropped on your site.
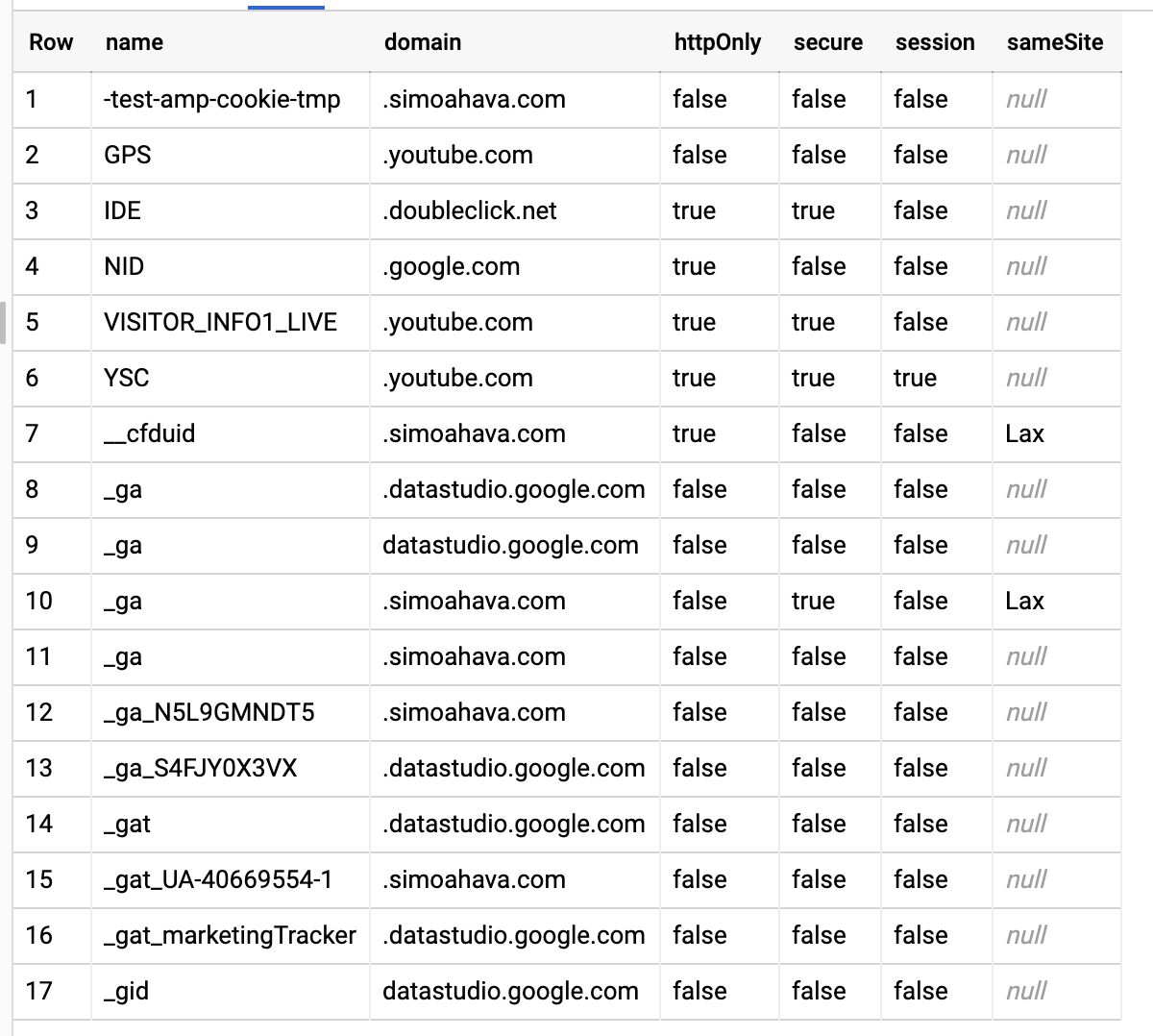
The purpose of this exercise is to list all the cookies, both 1st party and 3rd party, the crawler encounters when automatically following links within your site. This way you have an idea of what cookie storage is actually being utilized on your site.
You can use this information to proactively audit and annotate the cookie use on your site, which is helpful in case you are striving for compliance with EU’s cookie regulation, for example.
The Simmer Newsletter
Follow this link to subscribe to the Simmer Newsletter! Stay up-to-date with the latest content from Simo Ahava and the Simmer online course platform.
How to set it up
This is the easy part: you follow the exact steps as outlined in the original article. The only change you might want to do is set the config flag skipExternal to true in the config.json file, which means that the crawler will no longer crawl external pages that are linked to from your site. This was originally done to get the HTTP status codes of external links, but as you’re focusing on a cookie audit, external pages would just add to the confusion.
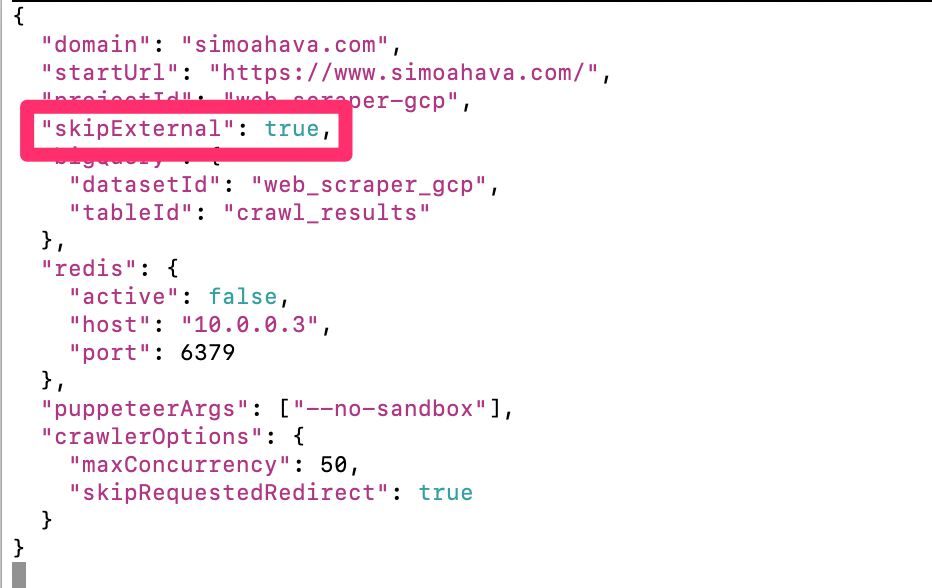
Other than that small change, just follow the steps in the original article. Just to recap, you should have the following:
- A Google Cloud Project with the necessary APIs enabled.
- The config.json file stored in a Google Cloud storage bucket.
- The
gce-install.shscript modified with the URL to the config file in the storage bucket. - Ability to run the command-line script that creates the virtual machine instance.
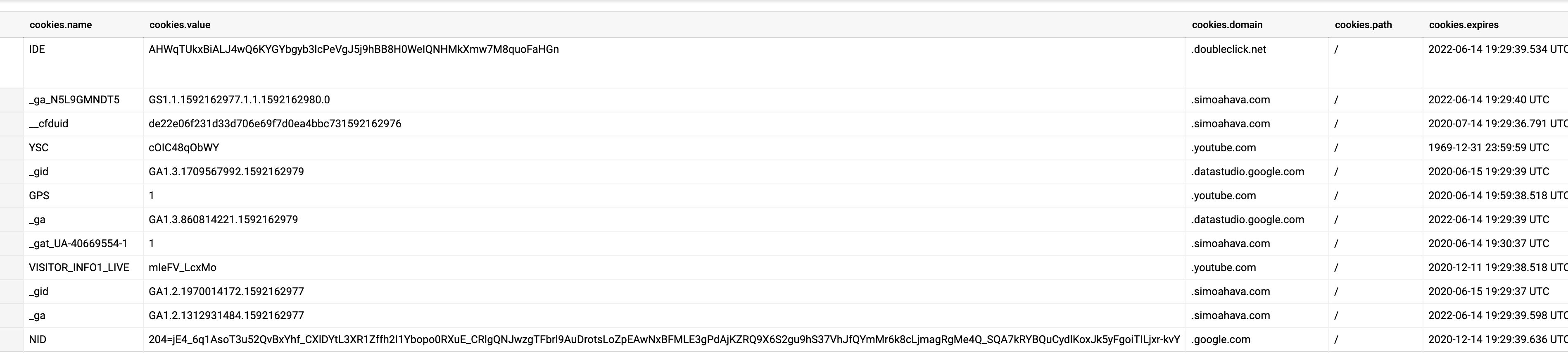
Once the virtual machine fires up, assuming you’ve followed the instructions meticulously, you’ll end up with a BigQuery table that collects a stream of scraped pages, together with the newly added cookie metadata as well.
{kind=link}
The crawler scans cookies in both 1st party and 3rd party requests. Cookie information is parsed for name, value, size, domain, path, expiration, HttpOnly, secure, and SameSite.
Sample queries
Once you have the data in the table, here are some BigQuery SQL queries you can run to make the most of the new information.
The first query is simple: it gets you the crawled URL together with all the cookies dropped on the site.
SELECT
final_url,
cookies
FROM
`project.dataset.table`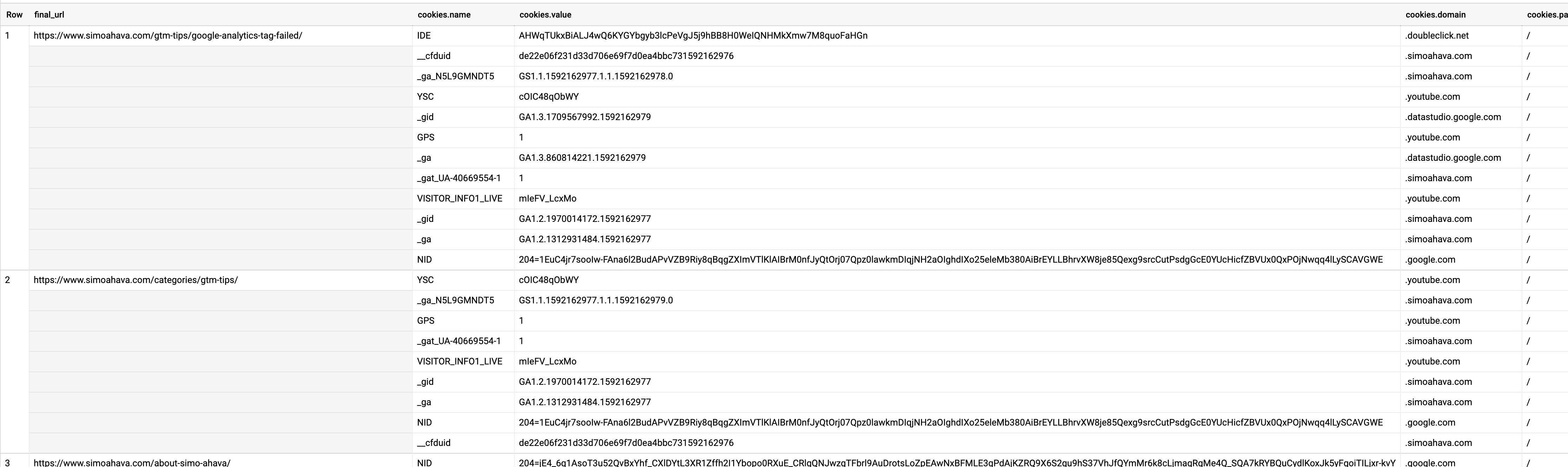{kind=link}
This second query returns just the cookies, grouping similar cookies together. It’s a handy way to get a list of all the distinct cookies dropped during the crawl. Each cookie with a domain namespace different from your own is a 3rd party cookie (unless you neglected to set the skipExternal flag to true in the configuration step).
SELECT
c.name,
c.domain,
c.httpOnly,
c.secure,
c.session,
c.sameSite
FROM
`project.dataset.table`,
UNNEST(cookies) AS c
GROUP BY
1, 2, 3, 4, 5, 6
ORDER BY
1 ASCYou can find a screenshot of the result at the very beginning of this article.
Caveats
There are some caveats to this solution.
Dynamic sites that reveal navigation links only upon a click, or that load content with lazy-load, will need to be manually configured into a custom crawler utilizing Puppeteer’s page APIs. It’s not trivial to set up, as you’ll basically need to add only the links scraped from a dynamic navigation click (or lazy-load event) into the headless-chrome-crawler queue to avoid duplication.
Another problem is that there might be cookies that are set only upon the user interacting with the site. Prime example is a login event, or a conversion event that doesn’t rely on a retargeting cookie (which would have fired with the page load). In these cases, a comprehensive cookie audit would need the crawler to be configured with these custom navigation paths, so that all cookies would be audited accordingly.
It’s also possible that some vendors can detect crawlers and prevent their SDKs from dropping any cookies.
In any case, the solution described here should be a starting point for a more comprehensive storage audit. It doesn’t tackle other forms of stateful storage (e.g. localStorage or IndexedDB), but it does give you an idea of what cookie storage the scripts and tags running on your site utilize.
Summary
Hopefully this article inspires you to take a look at the web-scraper-gcp project again, especially with the updated cookie crawling capabilities. I believe every single organization in the world should be exercising this type of oversight and governance in the name of accountability. You owe it to your site visitors. And, if your practices fall under legal regulation from e.g. GDPR or California’s CPRA, you should be very interested in knowing what browser storage is utilized on your site.
The headless-chrome-crawler project hasn’t been updated for a couple of years, but it still works. I’m hoping to fork it one day and fix the dependency issues, which you might have noticed if running the solution locally.
Let me know in the comments if you have questions or feedback about the solution - I’m happy to help if I can!