Updated 1 October 2019 With ITP 2.3 it looks like Safari is reducing the usefulness of
localStorageas well, so using that as an alternative fix to persistence issues should not be considered future-proof. this solution should not be considered future-proof.
Updated 12 March 2019 with some minor clarifications..
On 21st February 2019, WebKit announced the release of the latest iteration of Safari’s Intelligent Tracking Prevention (ITP), known as ITP 2.1. For a while now, Safari has been targeting cross-site tracking with ITP, first starting with cookies in third-party contexts, then tightening the noose after a number of workarounds emerged, and finally with the latest iteration targeting cookies that were moved from a third-party context to a first-party context.
{kind=link}
ITP 2.1 has one specific feature that will make us web analytics folks tremble in our boots:
With ITP 2.1, all persistent client-side cookies, i.e. persistent cookies created through document.cookie, are capped to a seven day expiry.
From the WebKit blog, emphasis mine.
This means that any JavaScript library wanting to store a cookie in the web browser will have that cookie capped to a seven day lifetime. After seven days since cookie creation, the cookie will expire and will be removed from the browser.
In this article, I want to explore the implications this has on web analytics, and what we can do to avoid losing the integrity of our data.
The Simmer Newsletter
Follow this link to subscribe to the Simmer Newsletter! Stay up-to-date with the latest content from Simo Ahava and the Simmer online course platform.
Brief introduction to ITP
In the following chapters, I will use these two terms:
-
Third-party context means that a resource is requested from a domain external from the one the user is currently on (i.e. they don’t share the same eTLD + 1), and this request tries to access cookies set on this external domain. Since the domain differs from the one the user is on (has to be a different root domain, basically), the interaction with this external domain happens in a third-party context.
-
First-party context means that a resource is requested from the current (parent) domain (eTLD + 1) the user is on. Since the user is in the same domain environment, any requests made happen in a first-party context.
ITP 1.0
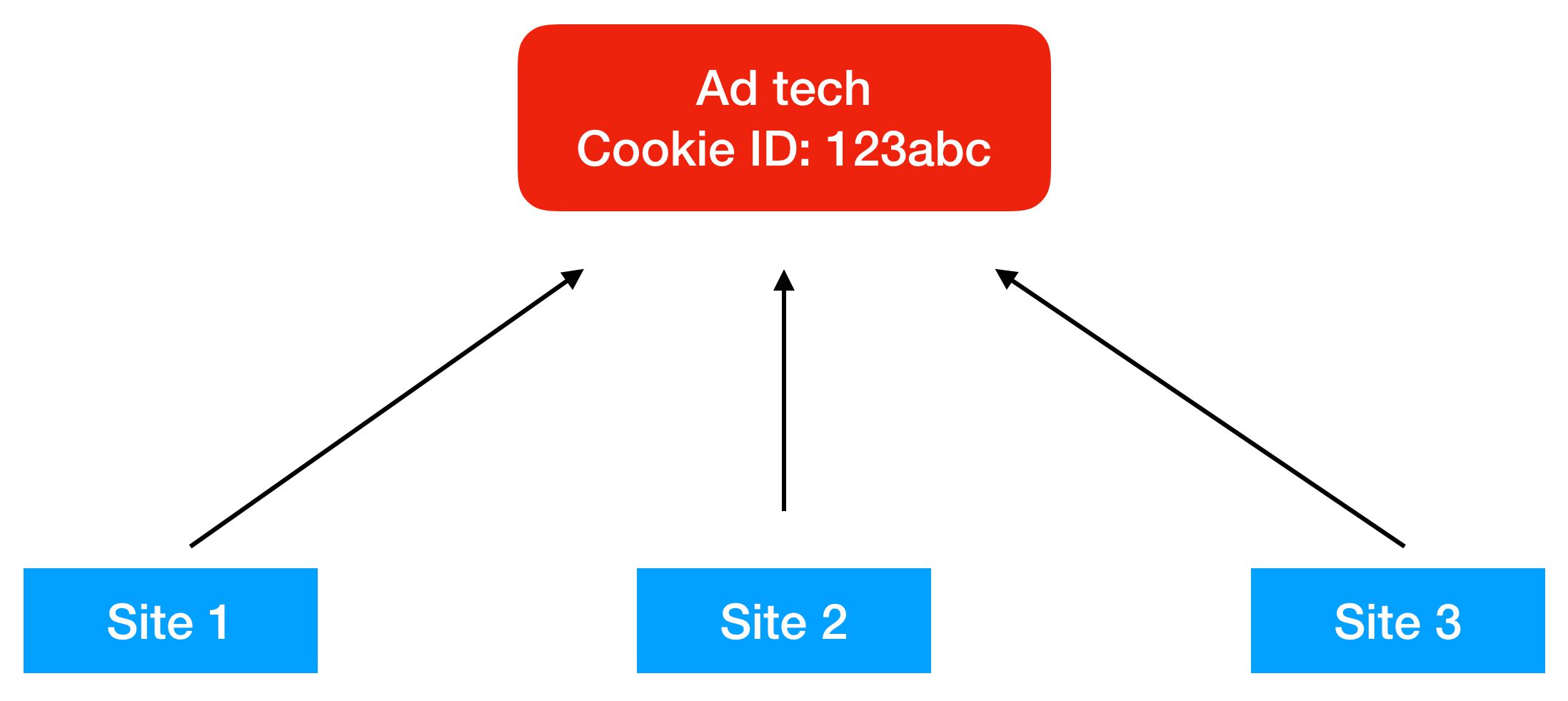
When Safari first introduced Intelligent Tracking Prevention, its mission was fairly clear. Safari wanted to prevent domains classified as having tracking capabilities from tracking users across different sites using third-party cookies.
A classic example is how advertising technology services might build an audience profile of their users by observing on which sites the user visits. This is done by having those sites call the AdTech domain with a pixel request or something similar, and a third-party cookie stored on the AdTech domain will thus be able to build a profile of the user based on the sites where the pixel was requested on.
{kind=link}
ITP made this more difficult by requiring that users actually interact with the third-party domain in a first-party context in order for the domain to be allowed to harvest their data in a third-party context. If there was no meaningful interaction such as loading the page and clicking on a button, a machine learning algorithm would classify the domain as having cross-site tracking capabilities, and as a result partition the cookies on that domain, preventing them from being used for cross-site tracking.
Remember: ITP’s main modus operandi is preventing cross-site tracking. It’s Intelligent Tracking Prevention, not Intelligent Cookie Prevention.
Naturally, for AdTech this is awkward. The whole point of pixel tracking is that it’s transparent and unobtrusive. What would you think if you were suddenly redirected to e.g. doubleclick.net and asked if it’s ok that Google continues to build an audience profile out of your web browsing behavior?
{kind=link}
But, third-party cookies can also be used for non-tracking purposes, such as maintaining a single sign-on (SSO) session. This is why the original ITP introduced a 24-hour grace period during which time the SSO cookie could be used in a third-party context. After that, the cookies should be stored in a first-party context or, preferably, by moving to HTTP cookies (more on this later) to avoid these issues altogether.
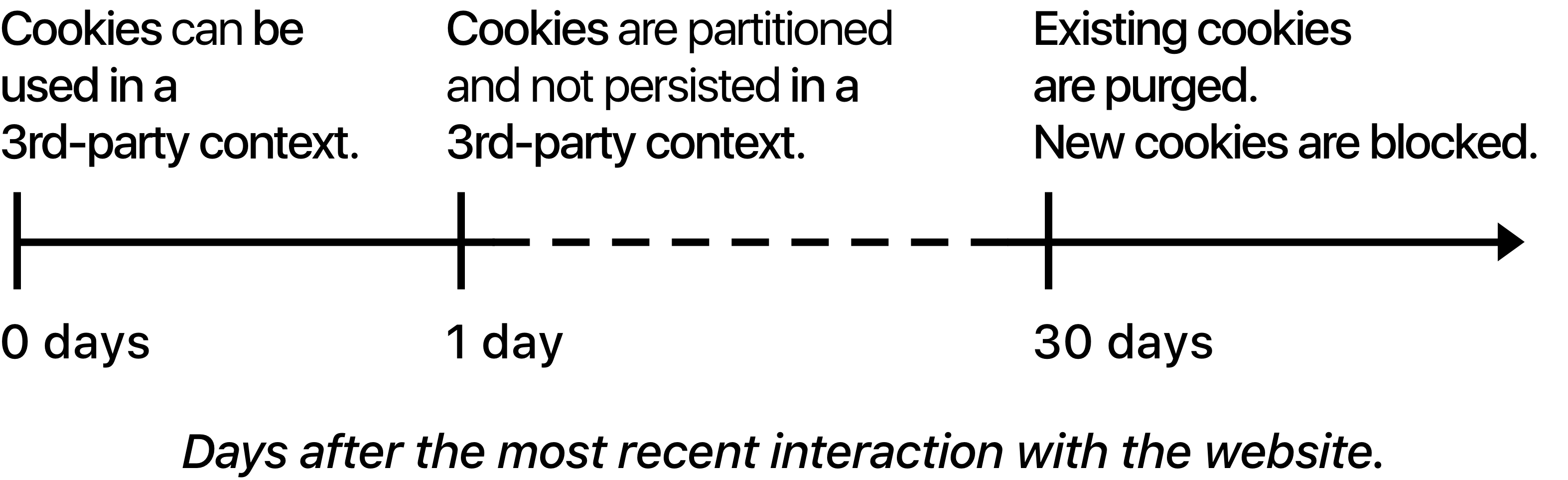
The cookies would be partitioned for 30 days. This meant that cookies used for tracking purposes get a unique storage double-keyed to the domain requesting the cookie (the first-party domain), and the domain setting the cookie (third-party domain). So, for example, a third-party cookie set by google.com while on simoahava.com would only be accessible when browsing simoahava.com. If the user went to younggoodmanahava.com, a separate cookie store would be created for that origin.
Partitioning the cookies this way meant that third-party cookies could still be used for things like login state management. Since the partitions are unique to each origin combination, cross-site tracking would effectively be neutered.
If the user visited the tracking domain within 30 days of the last interaction, both the 24-hour grace period and the 30-day partition timer would be reset.
If the 30-day limit expired without interaction with the tracking domain, all cookies would be purged from the tracking domain.
ITP 1.0 wasn’t very impactful for us Google Analytics users. GA works in a first-party context, so ITP’s updates did not concern us.
ITP 1.1 and Storage Access API
With ITP 1.1 and the Storage Access API, ITP made some concessions to third-party services serving embedded content, such as social logins or video services. It would be weird to have the user visit these services in a first-party context, because the whole purpose of embedding content is to do it smoothly while staying on the same site. The Storage Access API was the solution, where embedded content would be given access to the cookies stored on the third-party domain as long as the embed followed certain rules:
{kind=link}
The Storage Access API did not prompt the user for anything - this was the major concession from WebKit.
Since the Storage Access API allowed access to the third-party domain’s own, non-partitioned cookies, the partitioned cookies preserved for things like login state management were demoted to session cookies, so they would get purged once the browser was closed. This meant that the Storage Access API was the main way to access persistent data in a third-party context.
Still no issues with first-party web analytics, phew!
ITP 2.0
Mid-2018, WebKit introduced ITP 2.0.
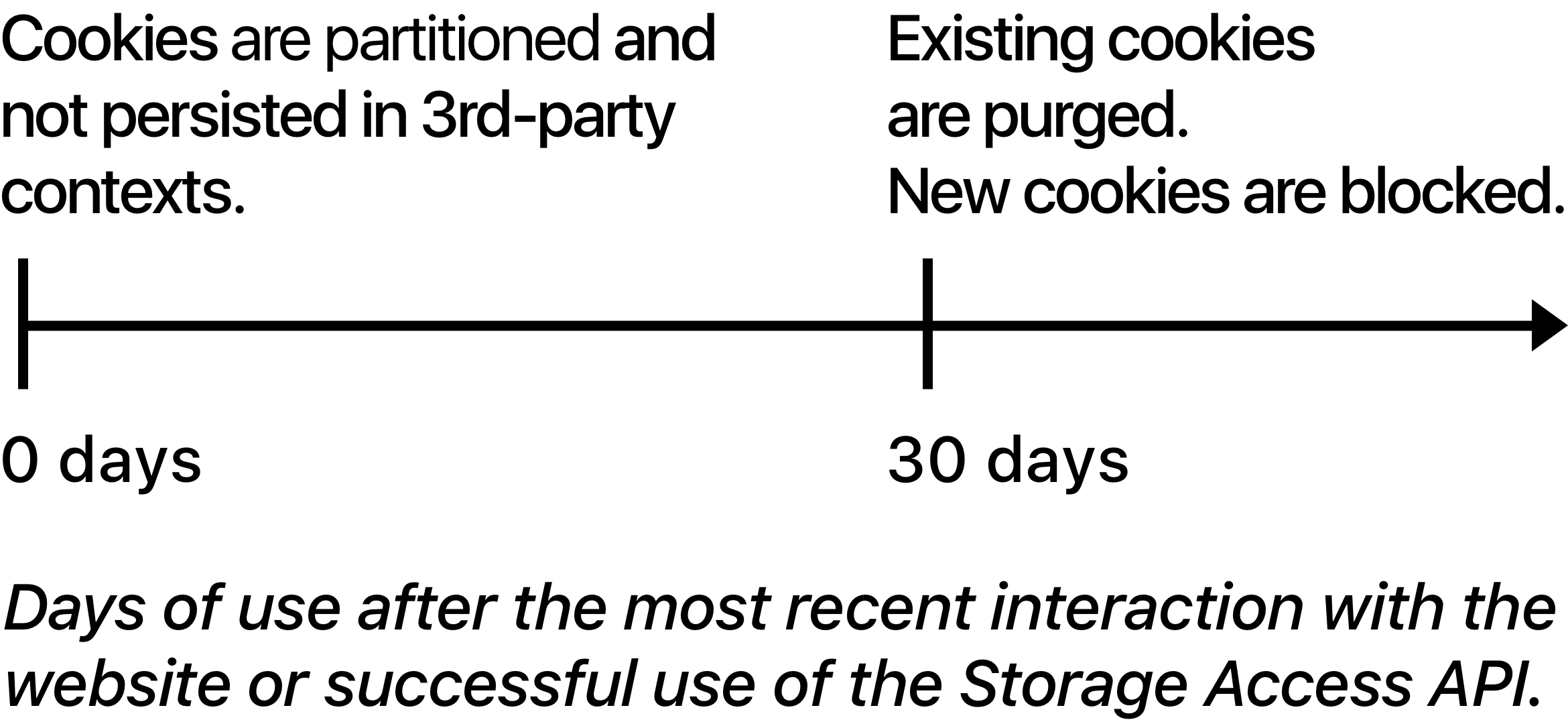
ITP 2.0 removed the 24-hour grace period altogether. Now cookies would be partitioned immediately after creation, if the domain was classified as having cross-site tracking capabilities.
{kind=link}
Another major thing ITP 2.0 did was make Storage Access API prompt-based. Instead of allowing embedded content to access cookies set in a third-party context by virtue of following the rules established in the previous chapter, Safari would now explicitly prompt the user for access to the third-party context. If the user gave access, the consent would persist and the 30-day timeline would be refreshed.
In other words, the Storage Access API was now the main way for domains classified as having cross-site tracking capabilities to access their cookies when embedded or requested in a third-party context.
First-party web analytics is still safe. But not for long.
ITP 2.1
ITP 2.1 was announced on February 21st, 2019, and it will come to effect as soon as iOS 12.2 and Safari 12.1 come out of beta.
Update 8 March 2019: It looks like features that are now bundled as ITP 2.1 have been quitely rolling out since the beginning of this year already.
ITP 2.1 removes partitioned cookies altogether. Now if a domain classified as having cross-site tracking capabilities needs to have access to its cookies in a third-party context, the Storage Access API must be used, even if used for things like login state management. The main purpose of this change is to reduce the amount of memory overhead that partitioned (session) cookies introduce on any given site.
But by far the biggest change in ITP 2.1, one that has direct consequences on first-party web analytics are the new measures placed on first-party cookies set with client-side JavaScript.
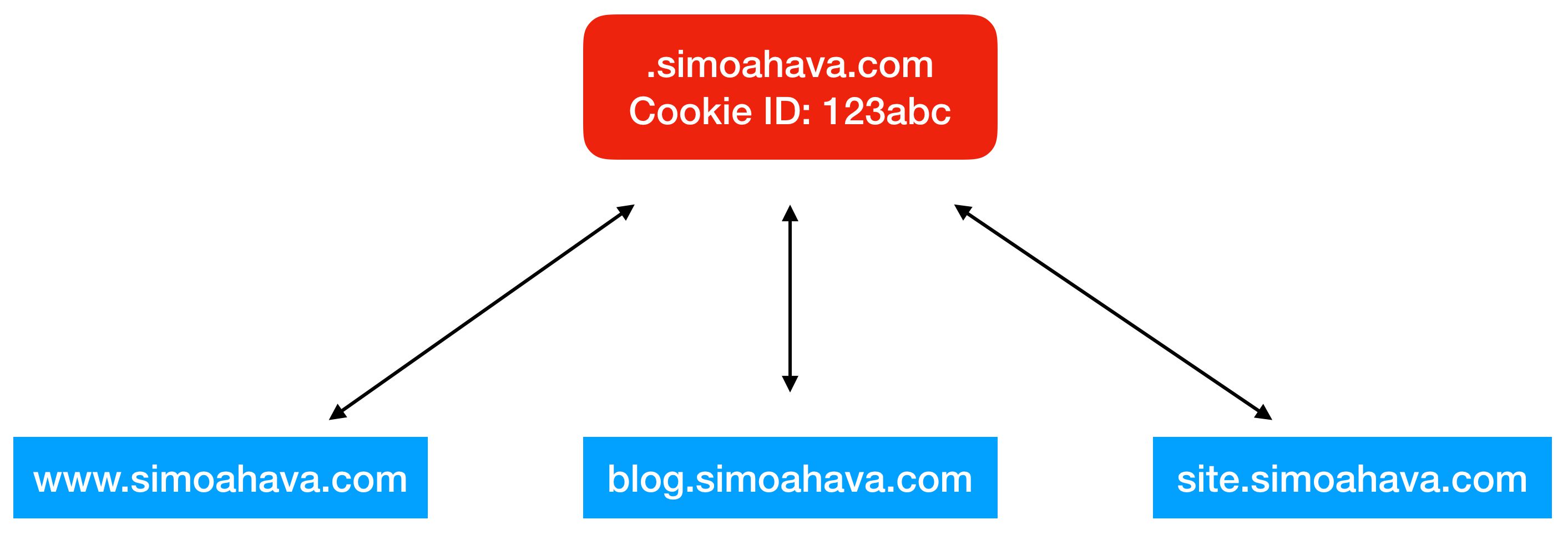
No longer is ITP just attacking AdTech companies who rely on cross-site tracking to build audience profiles. Now cookies set with document.cookie will also be targeted to prevent them from being harvested on different subdomains than the one on which they were set.
{kind=link}
As in the above example, any one of the subdomains of simoahava.com can write a first-party cookie on that root domain, after which any subdomain of simoahava.com can access that cookie. This is nothing new - this is how cookies set on a root domain have always worked.
However, ITP now targets cookies set with JavaScript’s document.cookie because it has become apparent that some vendors (e.g. one whose name rhymes with lacebook) have begun repurposing first-party cookies to help with their cross-site tracking intentions. They are also taking advantage of the scenario depicted in the image above. Even if you limited these vendors’ pixels to fire only on a specific subdomain, they could still access cookies on higher-level domain names.
The impact on web analytics is brutal, depending of course on Safari’s share of your traffic. Take the following example:
-
Day 1: User visits
www.simoahava.com, the_gacookie is written on simoahava.com. It is set at a 7-day expiry (rather than the 2 years that analytics.js defaults to). -
Day 3: User visits
blog.simoahava.com. The_gacookie is found on simoahava.com, so its value is available to blog.simoahava.com, and the 7-day expiry is reset. -
Day 13: User visits
www.simoahava.com. The_gacookie has expired, so a new Client ID is generated in a new_gacookie, and the visitor is treated as a new user in Google Analytics.
Google Analytics uses document.cookie to set the cookie in the browser. It really has no other choice. It’s a vendored JavaScript library, downloaded from Google’s servers, so it has no capability of setting e.g. HTTP cookies on simoahava.com, since they would be set in a third-party context.
Funnily enough, ITP 2.1 removes support for the Do Not Track signal in Safari, denoting the end to this miserable experiment in WebKit. Had more sites respected DNT when determining should visitors be tracked or not, perhaps we wouldn’t have seen ITP 2.1 in its current shape.
But because sites can’t be trusted to handle privacy and tracking prevention on their own, Safari must now take the reins and do it for them.
Technical implications and solutions
First of all, ITP 2.1 really only impacts browser cookies set with document.cookie. It will not impact other DOM storage (such as localStorage), because those are same-origin only, so lacking the capability of working across sub-domains. Similarly, it will not impact cookies set with HTTP responses, i.e. using the Set-Cookie header in the HTTP response.
HTTP cookies require a server-side script (or an edge cache / serverless solution) to modify the HTTP response, so it’s a deliberate decision from the site owner to set the cookies in the first-party context rather than a JavaScript library downloaded from a CDN being able to, at whim, set and get any first-party cookies it wants to. I suppose this is why they are not (yet) impacted by ITP.
localStorage for same-domain browsing
Update 1 October 2019: With ITP 2.3,
localStorageshould not be considered a viable solution for persisting client-side state anymore.
Many suggested using localStorage to persist these anonymous identifiers used by Google Analytics, for example. Instead of dropping a cookie named _ga, use window.localStorage.setItem() instead.
I was excited about this option, and even wrote an article that describes this possibility in detail.
However, the main issue is that localStorage is same-origin only. The storage in www.simoahava.com will not be available on blog.simoahava.com.
Thus the only thing that localStorage actually solves is not having the 7-day expiration cap on data stored on a single domain. Since all my web traffic happens on www.simoahava.com, localStorage is a good option for me, since it persists the Client ID nicely (though with some caveats nevertheless).
localStorage for cross-subdomain browsing
Thanks to Eike Pierstorff and Fujii Hironori for suggesting this solution.
An alternative option to same-domain localStorage is to create a store on a page in one of your subdomains, and then load that page in an iframe element, utilizing the postMessage API to get and set persistent cookie values on your site.
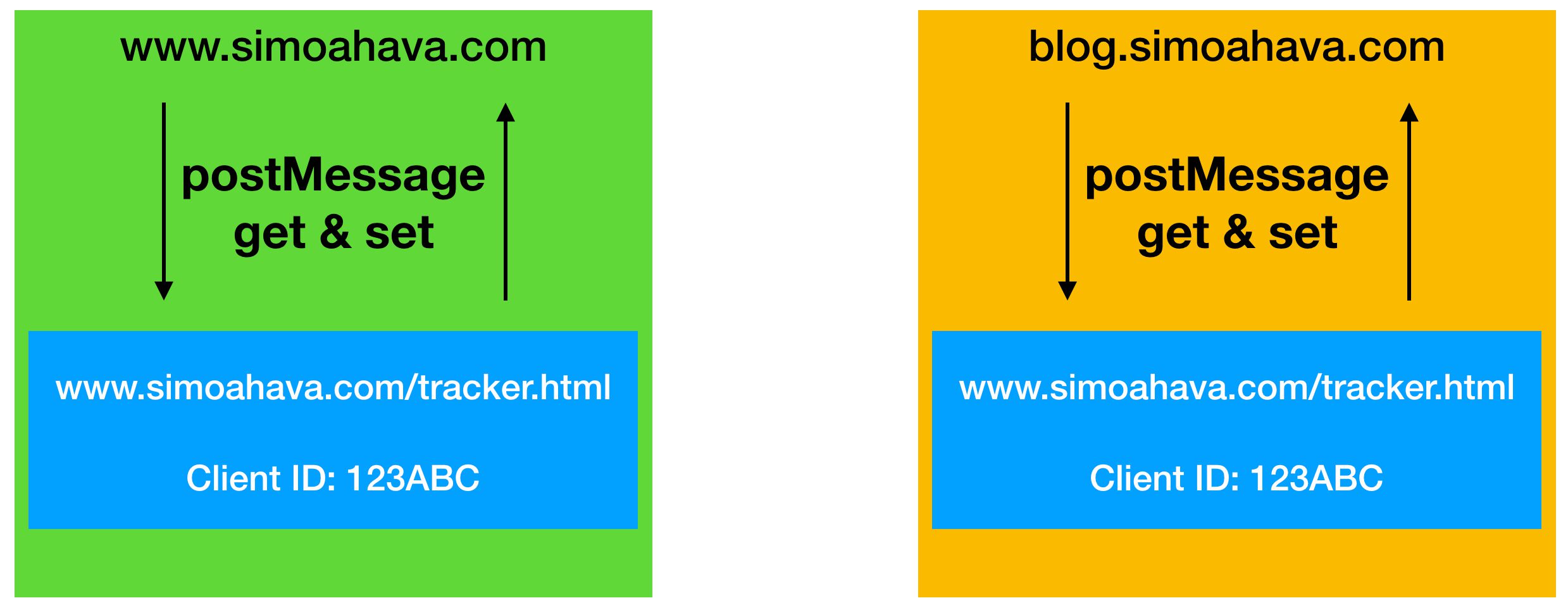{kind=link}
Since the localStorage store shares the same parent domain eTLD + 1 with the pages making the requests through the iframe, the interaction happens in a first-party context, and the localStorage store can be accessed without the Storage Access API. Also, in third-party contexts, localStorage is transient in Safari, meaning it is purged after the browser is closed. In first-party context this is not the case.
The process would look like this.
-
The page wanting to access the store would load the tracker page in an iframe, and send a message to it requesting a stored Client ID.
-
The iframe checks if it has the Client ID stored. If it does, it returns it in a message back to the origin page. If it doesn’t, it returns a string indicating this.
-
On the origin page, a listener listens for the response. If the response has a Client ID, that is used in the trackers running on the page. If the response has a “null” indicator, the origin page builds the Client ID, and finally sends it with another message back into the iframe for storage.
Here’s what the parent page script would look like:
// Create iframe
var el = document.createElement('iframe');
el.src = 'https://www.maindomain.com/tracker.html';
el.setAttribute('style', 'width:0;height:0;border:0;border:none');
document.body.appendChild(el);
// Add listener to get the stored Client ID
window.addEventListener('message', function(e) {
if (e.origin !== 'https://www.maindomain.com') { return; }
if (e.data === 'null') { generateTracker(null); }
else { generateTracker(e.data); }
});
// Send request to get the Client ID
el.contentWindow.postMessage('get', 'https://www.maindomain.com');
// Send message to set the Client ID after the tracker has generated one
function trackerGeneratedCallback(clientId) {
el.contentWindow.postMessage(clientId, 'https://www.maindomain.com');
}
Here, the iframe is generated, after which a message is sent to the iframe to get the Client ID. A listener on the page then waits for the iframe to respond. If the iframe responds with a 'null' message, a new tracker is generated (generateTracker) with its default Client ID generation mechanism.
If the iframe responds with the stored Client ID, then a new tracker is generated with this stored Client ID instead.
If the tracker did generate a new Client ID, then the trackerGeneratedCallback is called afterwards, and this sends the Client ID to the tracker page for storage.
And this is what the iframe page would look like:
<html>
<head>
<meta name="robots" content="noindex,nofollow">
<script>
// Check the request comes from *.maindomain.com
var hostNameRegex = /^https:\/\/([^.]+\.)maindomain\.com/;
function processMessage(event) {
if (!hostnameRegex.test(event.origin)) {
return;
}
// If request is to get the clientId, send it as a message back to the source page
// or send 'null' if no Client ID is found.
if (event.data === 'get') {
event.source.postMessage(window.localStorage.getItem('ga_client_id') || 'null', event.origin);
return;
}
// Otherwise, set the Client ID in localStorage using the message content
window.localStorage.setItem('ga_client_id', event.data);
return,
}
// Add a listener to listen for postMessage messages
window.addEventListener('message', processMessage);
</script>
</head>
<body>
</body>
</html>This way you could persist any client-side cookie values in the localStorage store of the domain where the iframe rests. This example is just for an arbitrary Client ID, but you could extend it for any value passed in the message.
Just remember the idiosyncracies of each platform. With Google Analytics, for example, additional measures need to be taken to handle cross-domain tracking, cookie expiration, etc.
Set-Cookie headers in a server-side script
Update 1 October 2019: This is definitely the most effective way to persist client-side state. See this article for inspiration.
Instead of setting the _ga cookie with document.cookie, you could instead set it with the HTTP response. For example, if running a node.js Express server, you could have the following lines in your code:
app.get('/', (req, res) => {
// Check for existing cookie and use that if found
let ga = req.cookies['_ga'];
// Check for linker and use that if valid
if (req.query['_ga']) {
ga = getClientIdFromLinker(req.query['_ga']) || ga;
}
// Otherwise generate a new Client ID
if (!ga) {
ga = generateGAClientId();
}
res.cookie('_ga', ga, {domain: 'simoahava.com', path: '/', secure: true, expires: new Date(Date.now() + 1000*60*60*24*365*2), });
res.render('index');
});
In this example, when the home page is requested from the server, its cookies are parsed. If the _ga cookie is found, its value is stored as a local variable. Then, if the request also has the cross-domain linker parameter, the parameter validity is verified (using e.g. my Gist) and if it’s a valid parameter, the local variable is overwritten with the Client ID from the linker.
NOTE! The
allowLinkerscript builds the fingerprint using, among others, the browser-based APIswindow.navigator.pluginsandwindow.navigator.language. As these are not available in the HTTP headers, you’d need to pass these to the server with the payload of the request you’d use to route the cookies, and then modify theallowLinkerscript to use these payload parameters rather than thewindow.navigatorAPIs. Alternatively, you could build your own cross-domain linker solution.
Finally, if the _ga cookie didn’t exist and if the cross-domain linker was missing or broken, a new Client ID is generated.
In the HTTP response, the _ga cookie is set with this value, and its expiration is reset to two years.
This type of server-side setup should be trivial to do in almost any web server environment (PHP/Apache, React, Node.js, IIS, etc.). But you do need access to the web server and its request handlers to be able to do this.
Set-Cookie headers in an edge cache
If you’re using a service such as Cloudflare, which caches your server content on “the edge”, you might also be able to run JavaScript to intercept and handle the HTTP requests between the browser and Cloudflare. On Cloudflare, this technology is called Cloudflare Workers. Amazon has a similar solution called Lambda@Edge.
The idea is that when the HTTP request for content comes in, a script running in the edge “rewrites” any cookies in the HTTP header with Set-Cookie, thus avoiding ITP 2.1 limitations.
Dustin Recko tackled this in a recent article on ITP 2.1.
Since many sites are already leveraging Cloudflare or Amazon’s Cloudfront, this would be a fairly lightweight way to handle the cookie routing.
Shared web service referenced with a CNAME record
Thanks to Lars Gundersen for nudging me about this idea.
This is super interesting. Apparently, it’s what Adobe has already been doing for a while.
The logic is similar to the server-side cookie router and/or the localStorage store described above. But instead of hosting the content on your own domain, you would create the endpoint in a virtual machine running in the Google Cloud, for example, and then create a CNAME record in your DNS to point tracker.mydomain.com to that virtual machine.
Then, when a page is loaded, the first thing it does is call this endpoint (tracker.mydomain.com). The endpoint would grab the cookies from the HTTP headers and use Set-Cookie in the response to write the cookies on mydomain.com, thus avoiding the ITP 2.1 ban on client-side cookies.
Alternatively, you could have tracker.html running in the service, and you’d load tracker.mydomain.com/tracker.html in an iframe, and use that as the localStorage store.
Naturally, this incurs some extra costs, because you would have to route a lot of calls to this cloud endpoint to make sure all the relevant cookies get their expiration extended. This is why, I guess, Adobe offers it as a service.
I’d be curious to see if this is something Google is looking at, too. Seems like it would be a somewhat elegant way to handle the problem with the _ga cookie. They could, for example, have analytics.js fetched from this CNAME redirected domain, but in addition to serving the library, it would also write the _ga cookie in a Set-Cookie response.
I verified with John Wilander (a WebKit engineer working on ITP) that this should be OK.
The problem here is that it adds quite a bit of overhead to the web service providing the response. For one, it would need to do the calculations for the _ga ID, but also it would need to process the request and customize the response. It’s possible that even if Google did do this, they wouldn’t offer it as part of the free Google Analytics service.
Reverse proxy to third party service
Thanks to Plamen Arnaudov for this suggestion.
A reverse proxy stands in front of web servers, masking their existence when the user requests for resources from a site. For example, a reverse proxy could forward a request for content to https://www.google.com/, but show https://www.simoahava.com/search-page in the URL.
It’s thus conceptually similar to the CNAME redirect, where the user is exploring content in their own domain namespace but the content is delivered from another origin.
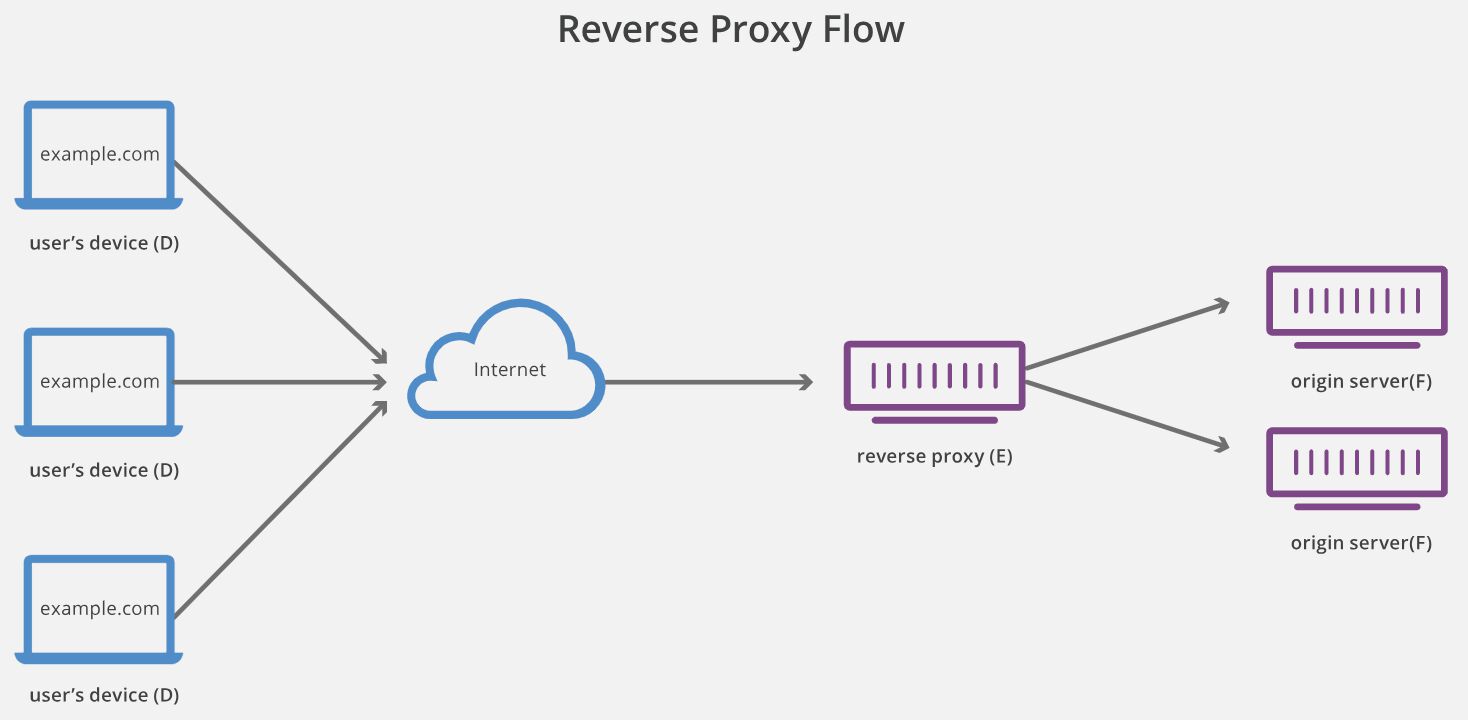{kind=link}
With the reverse proxy, a service like Google Analytics should need to modify some endpoint to either rewrite the _ga cookie in the request header with a Set-Cookie response, or create the cookie upon the request and serve it with the HTTP header. It might make sense, for example, to have the request for analytics.js respond with the Set-Cookie header.
We have the same limitations here as with the CNAME option above. Google would need to process the request before returning the header. Considering how many millions of requests to their services are made daily, any type of extra processing they’d need to do would reflect in costs.
The main difference between this and the CNAME option is that a reverse proxy requires the site owners and developers to add the server-side logic for the proxy, whereas CNAME requires just a DNS record change.
Setting up a reverse proxy isn’t complicated at all - with a Node.js server, you could do it with http-proxy-middleware in just a couple of lines:
const proxy = require('http-proxy-middleware');
...
app.get('/analytics.js', proxy({
target: 'https://www.google-analytics.com/',
changeOrigin: true
});
This would essentially perform the GET request for the analytics.js library on Google’s domain, but serve its content under your domain’s /analytics.js URL. If Google plays along, it could serve as a valid solution especially in cases where you can’t add any more CNAME records to your DNS.
Server-side analytics
There have been an array of suggestions using terms like server-side analytics, but I think these have misunderstood what ITP 2.1 does.
If there is no authentication against a backend, the user’s browser is identified with an anonymous identifier set in a cookie. No matter what type of analytics server is used - third-party or first-party - it’s this browser cookie that tells the service the user is the same as the one who visited some other page 5 minutes ago.
Changing the endpoint from www.google-analytics.com/collect to proxy.simoahava.com/collect, or changing from www.google-analytics.com/collect to snowplow.simoahava.com/track doesn’t change this dynamic. There’s no way to really align requests sent from a browser with requests sent by the same browser without having this identifier binding those two together somehow.
And if that cookie is set with document.cookie, it will fall under the 7-day expiration schedule, meaning two requests spread more than 7 days apart will not be able to enjoy the same cookie value any more.
The only way any server-side solution would work is if cookies were set with HTTP requests instead of with document.cookie. At this point, it might be easier to setup a cookie router, a CNAME redirect, or with a reverse proxy.
Final thoughts
I have many thoughts on this topic. Many, indeed. So let me list them here:
This is a good thing…
I think anything that questions the validity of browser cookies is a welcome disruption.
It’s not just those set with document.cookie. An overwhelming amount of sensitive information is still stored in cookies that do not use the HttpOnly and Secure attributes. See this piece by Mike West from Google if you want to be depressed (and there’s some cool suggestions for going forward, too).
Anything that makes life even more difficult for AdTech gets a solid thumbs up from me. Turning third-party data leeching into a consent-based prompt via Storage Access API is a great way to give users the reins.
For sites with authentication, this makes it even more prudent to incentivize a login. If a user logs in to the service, no cookies are even needed, since a persistent User ID could be used as the user’s identifier sent to analytics platforms (as long as the user’s consent for this is requested and as long as the tracking only happens when they’re logged in).
…but perhaps the baby was thrown out with the bathwater
I can’t help thinking that benevolent first-party analytics gets hit with collateral damage here.
I had some exchanges in Twitter with the WebKit engineer working on ITP (John Wilander), and this is one of the things he responded to me with.
I totally agree with cross-site tracking being generally bad. But there are ways to do web analytics without malicious intent. It would have made more sense to prevent cookies from being accessed outside the domain they were set on, thus forcing sites to append linker parameters to internal links, but expiring all document.cookie setters with a 7-day cap is pretty drastic.
Having Google Analytics running on your site does not make you a bad person - you are using it to optimize the performance and usability of your site, and for creating better landing pages and marketing campaigns. But now that the cookie is capped at 7 days, you basically lose all ability to build cohorts of users who only visit your site once a month, for example, unless you invest in setting HTTP cookies instead.
John’s later tweet clarified this.
So it does seem that ITP is taking blanket measures to best target the bad actors in the industry.
And this is definitely not the last of it
It’s not just ITP. Firefox will also start blocking cross-site third-party trackers, no doubt taking a leaf out of ITP’s book. They’ve already had a very strong-armed approach to blocking trackers (though in private browsing mode only, for now), so this doesn’t come as a big surprise.
Update 8 March 2019: Firefox announced they will start experimenting with the 7-day expiration of JavaScript cookies, too.
As workarounds for ITP are invented, new iterations of ITP will be introduced. Until now, each iteration has made ITP stricter. Even if they made a concession (Storage Access API without user prompt), they seem to not hesitate to pull it back in a later version.
I don’t think they’ll let go of the 7-day cookie expiration for document.cookie. If anything, they’ll reduce it to just one day, or only allow session cookies. Or, perhaps eradicate JavaScript cookies altogethe. In any case, it’s up to vendors and their enterprise clients (since money talks) to consider how big a deal this is, and how to solve this going forward.
Adobe has already introduced their own ways of tackling ITP but with the ban on document.cookie it remains to be see how they’ll react to ITP 2.1.
Vendors might be hesitant to take action because nothing is future-proofed. Any solution that caters to web analytics users could be misappropriated for cross-site tracking purposes, and at that point a future iteration of ITP would most certainly neuter it. And if that happens, the analytics vendor who encouraged enterprise clients to spend thousands of dollars in implementing the solution will now be blamed for not having enough foresight.
Going forward
To sum up this article, here are the key takeaways:
-
If you are tracking just root domains, and do not need cross-subdomain tracking to work without explicit linker parameters, you can use the
localStorageworkaround. See this chapter for more information. -
If you think Safari has a big enough share of your traffic to seriously impact your data quality, you should look into writing the
_gacookie using HTTP cookies. See here for a recap. -
Follow John Wilander on Twitter.
-
Await an official announcement from Google (or whatever your favorite analytics vendor is) on how they intend to tackle ITP’s stranglehold on cookies written with
document.cookie.
For a geeky tech dude like me, we’re living in some pretty cool and exciting times. Having to figure out workarounds for this concentrated attack on cookies by (most) web browsers is inspiring!