It’s time for MeasureCamp again! As before, I want to write an accompanying post for my session, since there’s always so much more to say than the time slot allows for. So, the topic of this article is the data model used by Google Tag Manager to process digital data in your data layer.
This post also picks up where I left in my previous foray into the data layer. However, where the first article aimed to be generic (since the data layer should be generic), this post will look at how GTM uses the information in the generic data layer, and how it processes this information to work with the proprietary features of the tool.
{kind=link}
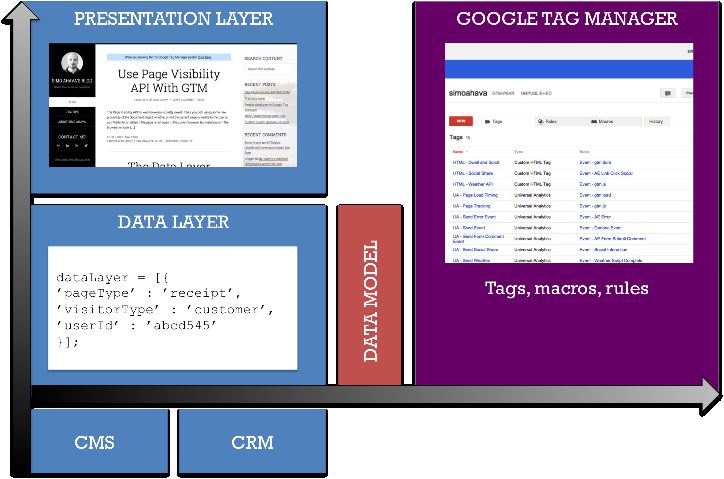
The diagram above should elucidate my point (fear my PowerPoint-to-image skills).
We have data passing through your backend systems to your website. Some of this data is used to build the website with its visuals and functionalities, and some of this data is stored in the data layer to be used by other tools and applications connected to the website.
Google Tag Manager doesn’t access the data layer’s structure directly, since that would compromise the data layer’s generic and tool-agnostic purpose. Rather, it pulls data from the data layer, stores it in its internal, abstract data model, and uses that to process the digital data.
Since we live in a multi-vendor world, where web tools and applications are popping up like mushrooms after rain, it’s important to respect the generic data layer. It’s up to the sophistication of the tool itself to use this data, but it must be done in a non-invasive manner - using pull methods rather than push.
| dataLayer | Data Model |
|---|---|
| Tool-agnostic | Tool-specific |
| Generic | Unique |
| Accessed directly | Accessed via helper |
| Structured | Abstract |
There’s a difference between data layer and data model. To some it might seem very subtle, but in reality it’s what ensures that the data layer remains a free-for-all, standardized container for data. The data model, on the other hand, is built according to each platform’s own specifications, but the way it communicates with the data layer must be clean and perhaps even standardized, since only that way can we ensure that a single tool doesn’t ruin the data layer for all.
The Simmer Newsletter
Follow this link to subscribe to the Simmer Newsletter! Stay up-to-date with the latest content from Simo Ahava and the Simmer online course platform.
Setting up the test
The most familiar way of accessing GTM’s data model is through the Data Layer Variable Macro. When you call this macro type, the following happens:
-
The macro polls the data model through an interface method
-
If a key with the given variable name is found, its value is returned
-
If no key is found,
undefinedis returned instead
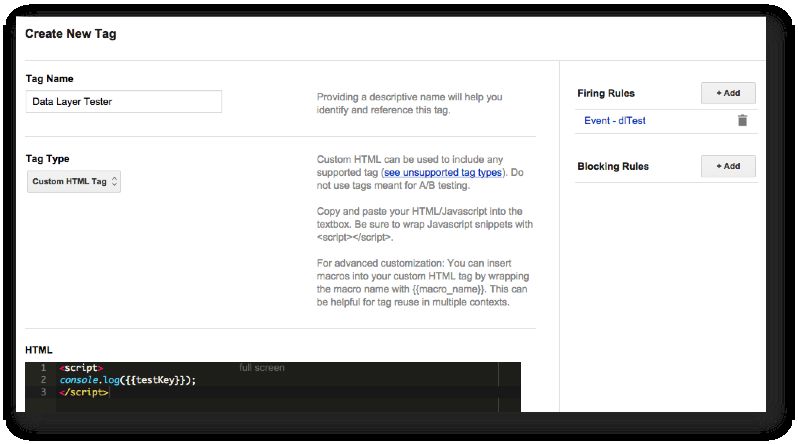
For the purposes of this article, I’ll now create a tester, which shows you how the data model works. The tester is a Custom HTML Tag which fires upon a certain event (‘dlTest’). When it fires, it prints the content of the Data Layer Variable Macro into the JavaScript console.
{kind=link}
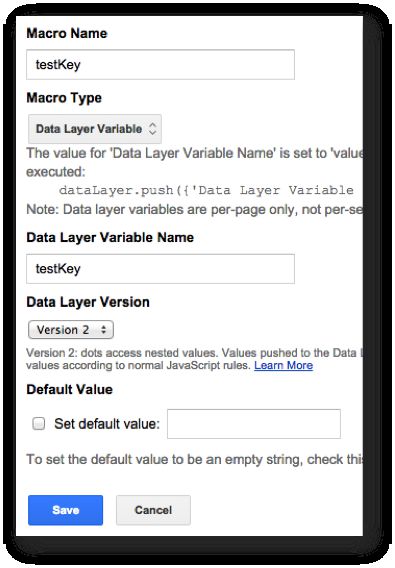
The macro itself is just a Data Layer Macro which refers to variable name testKey:
{kind=link}
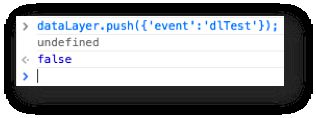
So now, whenever I want to see what the key testKey contains in the data model, I only have to type the following in the console:
dataLayer.push({'event' : 'dlTest'});
Next, I’ll publish my container, and try this out. This is what the console looks like now if I run the event:
{kind=link}
The undefined is what the macro actually returns. false is returned because the event push triggered a tag.
Add and modify the key
Let’s start simple. I’ll add some values to the key, and see how the macro reacts:
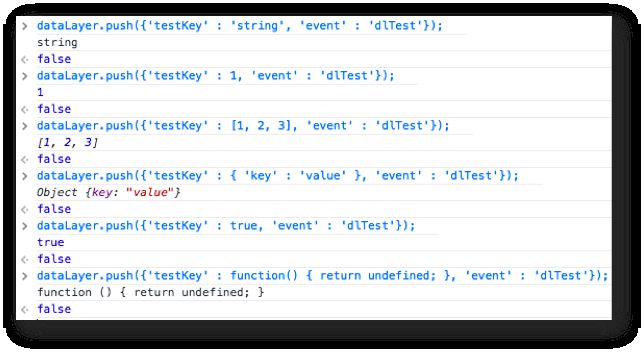{kind=link}
Here are the pushes in order:
-
'string'- string -
1- number -
[1, 2, 3] - Array -
{'key' : 'value'}- object -
true- boolean -
function() { return undefined; }- function
As you can see, the interface get() function only returns the latest value. dataLayer, however, holds all the values:
{kind=link}
Here are the key takeaways:
-
The data model is not the same thing as data layer. All the values I pushed above can be found in the data layer, but only the most recent value is stored in the data model
-
When pushing a value of different type, the previous value is completely overwritten in the data model
That’s pretty simple, right? Well, let’s try updating the value with another value of the same type next.
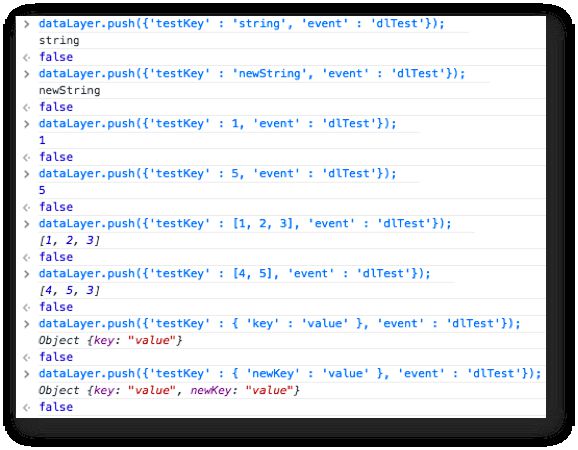{kind=link}
Here are the pushes in order:
-
'string'+'newString'=>'newString' -
1+5=>5 -
[1, 2, 3]+[4, 5]=>[4, 5, 3]*HUH? -
{'key' : 'value'}+{'newKey' : 'value'}=>{'key' : 'value', 'newKey' : 'value'}*WTF?
The primitive values work as expected. Pushing another value of the same type just overwrites the previous value. However, the Array and the plain object behave very strangely.
This is because when you’re pushing an Array on top of an Array or a plain object on top of a plain object, the interface performs a recursive merge. That is, it checks whether the keys within the object or Array that are being pushed already exist. If they do, their values are updated, but all the other keys are left alone.
It’s easy to understand if you look at how the plain object behaves.
First, you push an object with the key ‘key’ with the value ‘value’. Next, you push an object with the key ‘newKey’ with the value ‘value’. Now, ‘key’ is not the same thing as ‘newKey’, so the plain object is updated, not replaced.
But what about the Array? I’m pushing [4, 5], which have nothing in common with [1, 2, 3]. Shouldn’t the end result be
[4, 5], or
[1, 2, 3, 4, 5], or even
[[1, 2, 3], [4, 5]]?
Surely [4, 5, 3] is a bug?
Nope, if you know your JavaScript. An Array is a type of an object. It, too, has keys with which you can access the values within. The keys start from 0 and go up until there are no more members in the Array. So, the first Array looks actually something like this:
[1, 2, 3]
Key 0 : Value 1
Key 1 : Value 2
Key 2 : Value 3
The second Array looks like this:
[4, 5]
Key 0 : Value 4
Key 1 : Value 5
Now, the recursive merge spots these shared keys (0 and 1), and updates their values accordingly. The third key (2) is not touched, since the Array that was pushed second had no value for it.
We’ll explore how to add data to existing Arrays soon enough.
Removing a key from the data model
If you have a single page app, and the data layer persist throughout the session, you might want to delete some variables from the data model every now and then. Just removing the key from dataLayer won’t be enough:
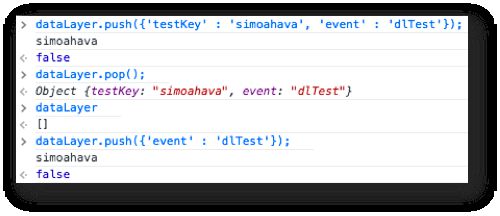{kind=link}
Here’s what happens:
-
I push ‘simoahava’ as the value of ‘testKey’, this is registered by the macro
-
I delete this entire object from
dataLayer -
I verify this by looking at the contents of
dataLayer -
However, the data model still holds the latest value
This is actually an important feature of the data model. The data model treats dataLayer as a queue or a message bus, if you will. It operates on a first in, first out principle, meaning that as soon as something is pushed into dataLayer, it is processed and its values are stored into the data model.
It wouldn’t work if the data model should remove a key if it is dropped from dataLayer. You might have multiple pushes of the same key with different values (take ‘event’, for example). How would the data model know if you’re just cleaning up objects from the global Array structure rather than asking for them to be removed from the data model?
A remove method in the interface might be a good idea, but it’s just as easy to take the generic approach and push undefined as the value of the key. This will store undefined into the data model as well, meaning it will be, for all intents and purposes, as if the key no longer exists.
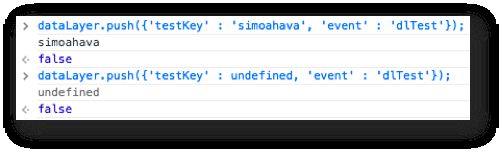{kind=link}
That’s how simple it is.
The command array
This is where I left you hanging earlier. Say you want to update an Array by adding members to the end or into the middle. It’s very difficult to do in a generic way, since you first need to retrieve the Array from the data model, add members to the end or to the middle, and then push it back. And all has to happen within the data layer, because you don’t want all the other tools and platforms that use the data layer to be left outside.
The way to do this is to use a special command array. It enables you to access methods of the value type you have stored in the data model.
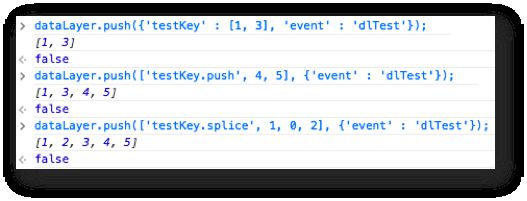
Here’s how it works. I’m going to update an Array [1, 3] first with two new members using push(), so that it becomes [1, 3, 4, 5]. Next I’ll do a splice(), where I add the number 2 to its rightful place. Observe closely.
{kind=link}
As you can see, the command array has its special syntax. First of all, you need to push an Array into the data layer, not an object as you normally would.
Next, the first member of the Array needs to be a string which holds the actual command. All the rest of the members in the command array are arguments to this command.
Thus, testKey.push(4,5) becomes ['testKey.push', 4, 5], and testKey.splice(1,0,2) becomes ['testKey.splice', 1, 0, 2].
This way you can do some cool things with the values stored in the data model without having to access them directly. Using the data layer ensures that other tools and applications can benefit from your modifications as well.
Custom methods
The last thing I’ll show you is how to perform some custom transformations on the values stored in the data model.
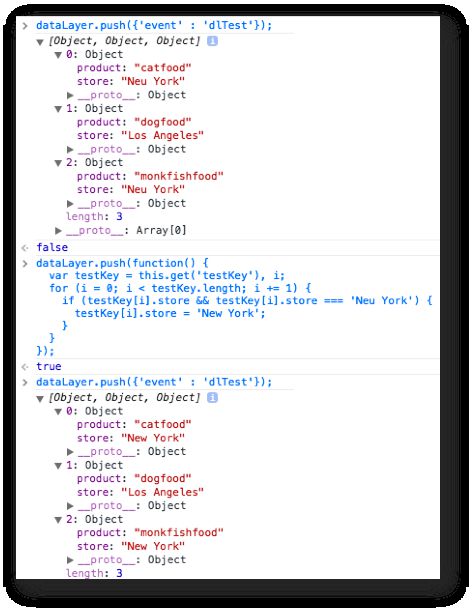
Let’s say I’m storing a bunch of products and stores in the data layer. This data is provided by the backend system. As it turns out, one of the store names is misspelled, and this needs to be fixed in the data model. Performing a series of gets and sets would be cumbersome and very ineffective. Instead, I can just push a function which does this whole thing in a simple for-loop.
{kind=link}
When you push a function into the data layer, this will be the interface of the data model on the page. It exposes two methods: get(key) and set(key, value).
First, I use get() to retrieve the value of 'testKey'. Then, I do a for-loop which goes over each member in the 'testKey' Array, looking for the typo. If a typo is found, then it’s corrected there and then. Because I’m dealing with objects, you don’t have to push anything back into the data model, since you’ve actually copied an object reference, not the object itself.
Don’t worry about that object mumbo-jumbo. The key here is that I performed a transformation on the data in the data model by using the data layer. This way other vendors and tools can benefit from the change as well. I could have just as well directly accessed the public method of the interface, but that would not be the generic way to do things.
Summary
This has been a complicated post, I know, but here are the things you should have learned.
-
The data layer on the page and the data model used by the tag manager are not the same thing
-
The data layer is generic, tool-agnostic, and can be accessed by all applications that can tap into the global namespace
-
The data model is internal to the tag manager, it’s abstract (no Arrays here), and it has a public interface with just two methods
-
Certain values (Arrays, plain objects) behave erratically when you try to update them with a regular push
-
You should always do all additions, removals, and transformations by using the data layer, and not by accessing the interface of the data model directly
If you want to geek it up a little, take a look at the Data Layer Helper specification in GitHub, written by GTM’s own Brian Kuhn. That’s where most of the lessons here were picked up.
It’s so important to understand the subtleties of the data layer and the data model. The one is (or should be) tool-independent, the other is a proprietary feature of the tool. One can be standardized to serve multiple vendors and platforms, the other should cater to the idiosyncrasies of each tool separately.
My presentation “Google Tag Manager For Nerds” from MeasureCamp V