With asynchronous variables recently released in server-side Google Tag Manager, it’s time to dig into data enrichment flows using another release from the Google team.
* drum roll *
We have a new Google Cloud Platform API!
It’s fast. It’s sleek. It’s beautiful. It’s Firestore!
{kind=link}
Firestore is a NoSQL, transactional, and scalable database that offers near-real-time write/read and sync operations for data.
In practice, it’s a great way to enrich and widen the data that you pass through your Server container.
The Simmer Newsletter
Follow this link to subscribe to the Simmer Newsletter! Stay up-to-date with the latest content from Simo Ahava and the Simmer online course platform.
What is Firestore
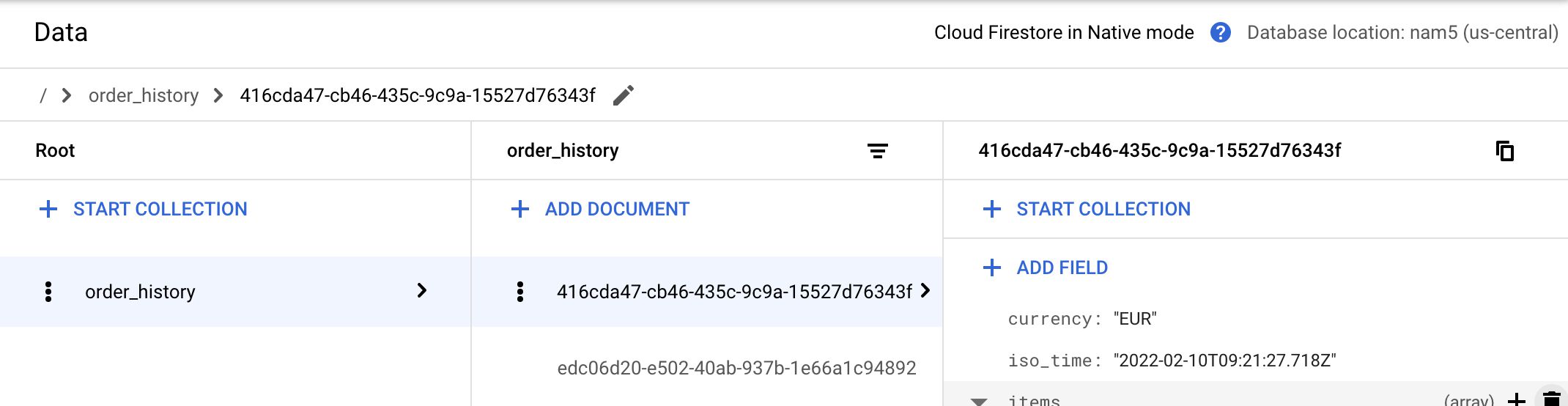
Firestore stores data in documents, each contained within a collection.
{kind=link}
Documents store data using familiar data types, such as strings, numbers, complex objects, and even subcollections for more hierarchical setups.
When querying the data, you can either directly reference a document by its path (e.g. order_history/416cda47-cb46-435c-9c9a-15527d76343f), or you can query the collection to fetch all documents that match the query (e.g. iso_time == "2022-02-10T09:21:27.718Z").
As such, Firestore has great utility for widening the data streams in the Server container.
{kind=link}
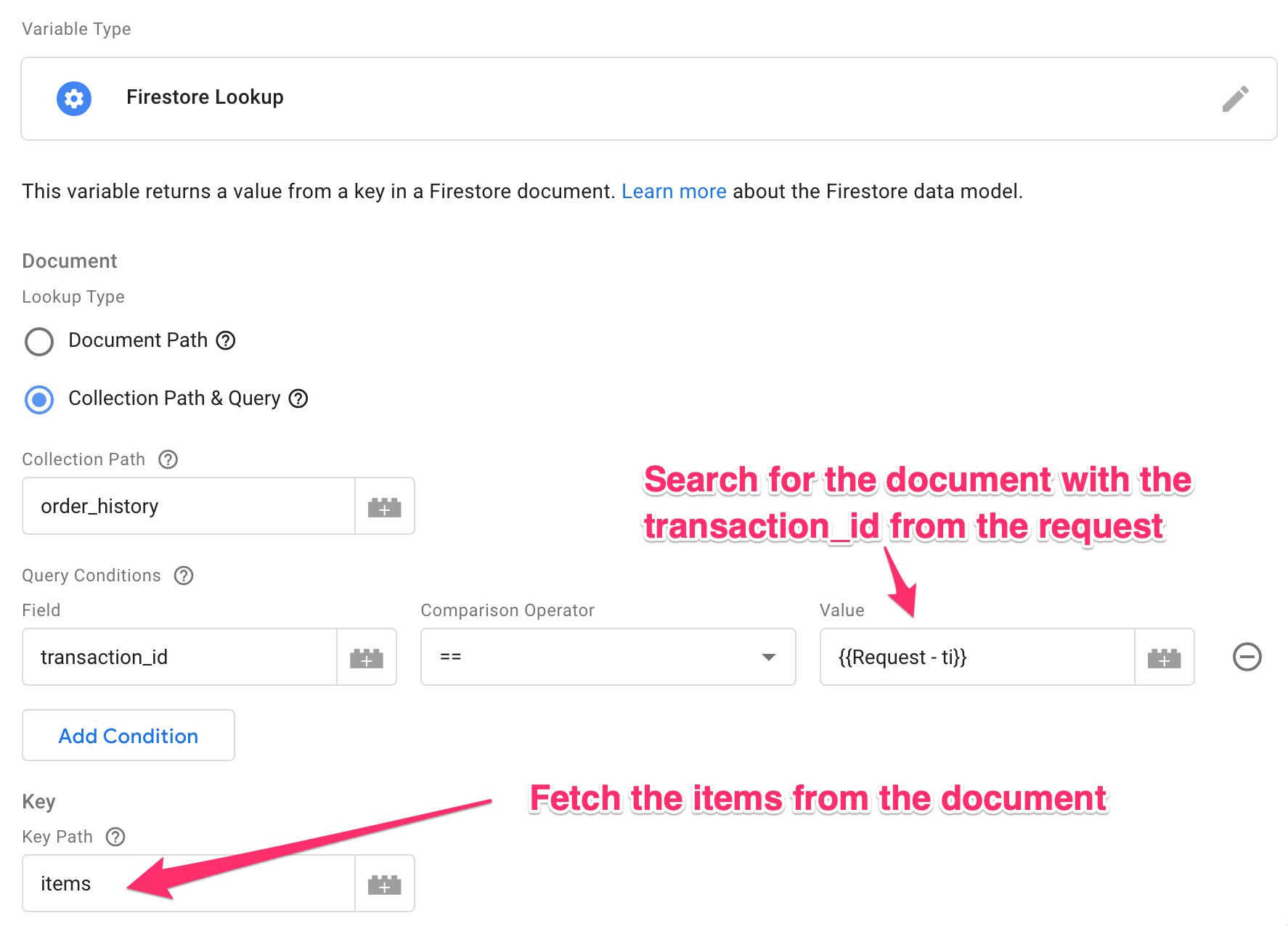
The incoming request can include a key, such as the transaction ID, and this key can then be used to query the Firestore for additional data.
{kind=link}
Thanks to the new asynchronous variables, this can all be done quite easily (see below for examples).
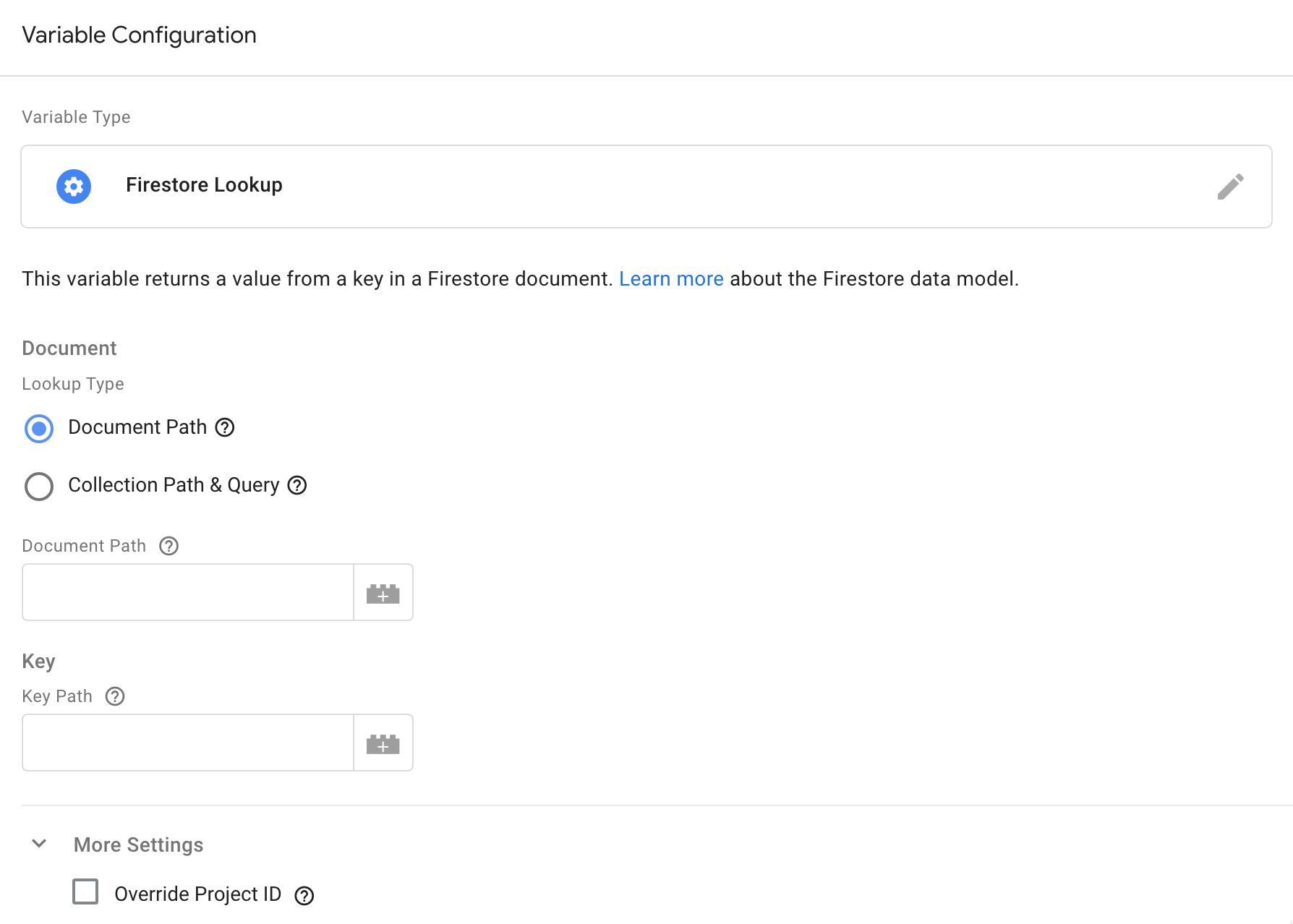
The new Firestore Lookup variable
To make it easy to read Firestore data, there’s a new Firestore Lookup variable in server-side Google Tag Manager.
{kind=link}
This variable lets you pull in the value from a specific key/field in a Firestore document.
Lookup Type
The Lookup Type specifies how the correct document is retrieved. If you recall, Firestore nests all the relevant information within a document, which is hosted in a collection.
You can fetch the document directly using the full Document Path, or you can search for the document with Collection Path & Query.
Specifying the Document Path is the fastest method, because it’s a direct lookup to fetch a single document.
The document path typically looks like this:
collection_name/document_name
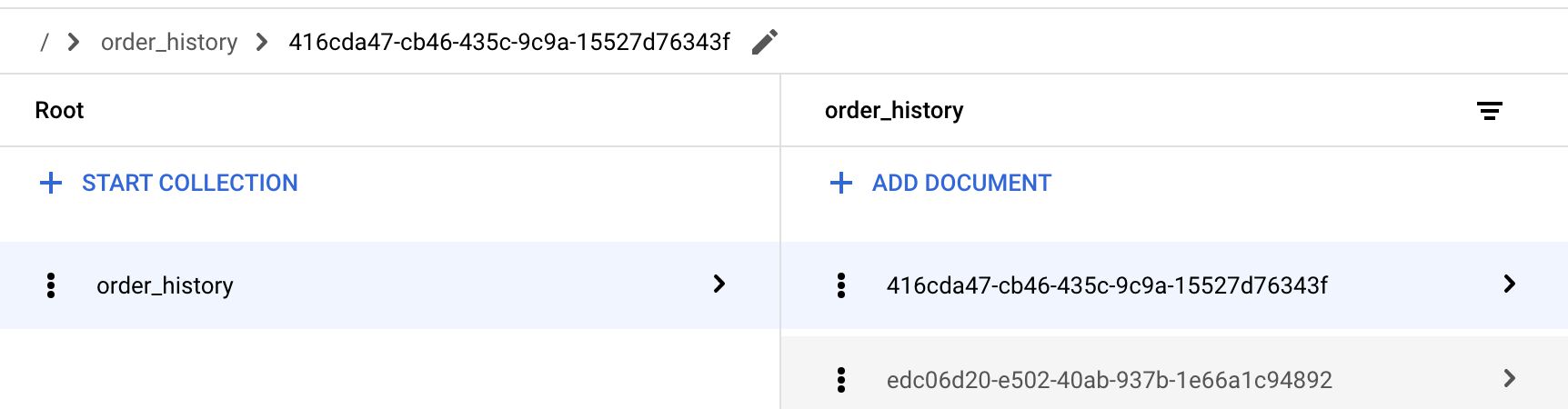{kind=link}
For example, to fetch the first document in the screenshot above, I would specify this as the Document Path:
order_history/416cda47-cb46-435c-9c9a-15527d76343f
Alternatively, if you can’t access the document directly with the path, you can also query it. You first need to provide a path to the collection that has the document. Then, you can add one or more query conditions using keys you know to exist in the document.
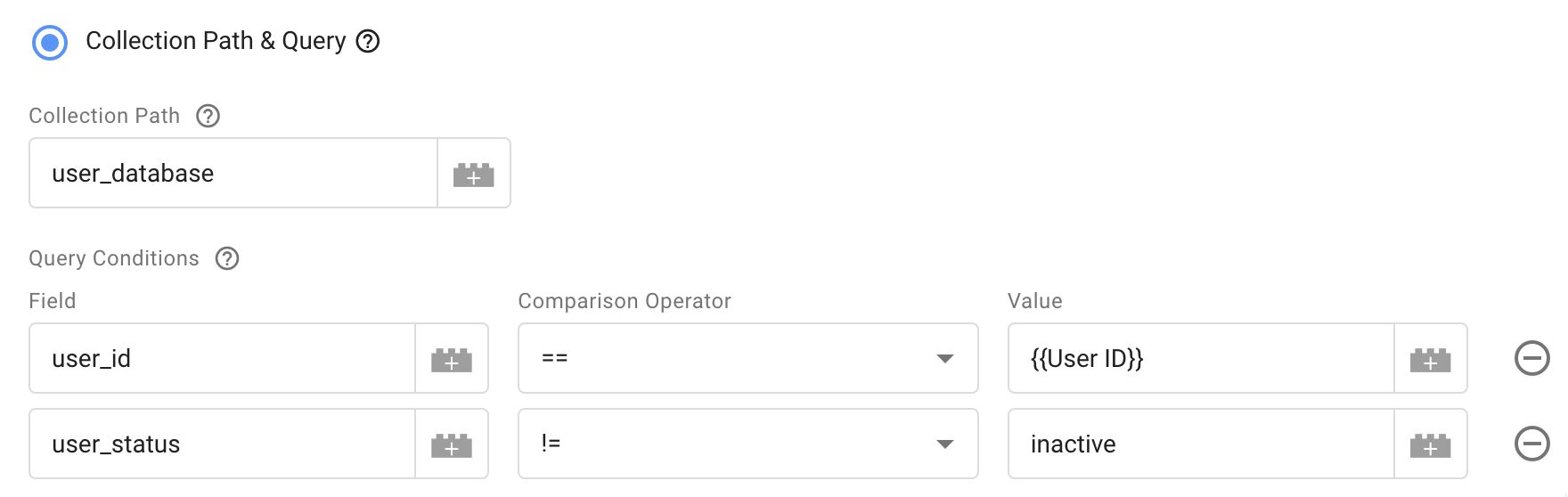{kind=link}
The query above would look for documents embedded within the user_database collection. The variable would fetch the first document that has the user_id field set to whatever is contained in the GTM {{User ID}} variable (could be something from the incoming request, for example) and has the user_status field set to something other than inactive.
Because Firestore indexes documents by default, query performance is proportional to the size of the result set and not the data set being queried. So it doesn’t matter how many documents there are in the collection for query performance, but it does matter how broad your query is (i.e. how many results it retrieves).
The Firestore variable uses the first document that matches the query for returning the key (see below). This is something to consider in case your query is too general and returns multiple (unrelated) documents.
Key Path
Assuming the lookup returns a document, the Key Path then specifies which value to fetch.
Here’s a dummy example of a Firestore document:
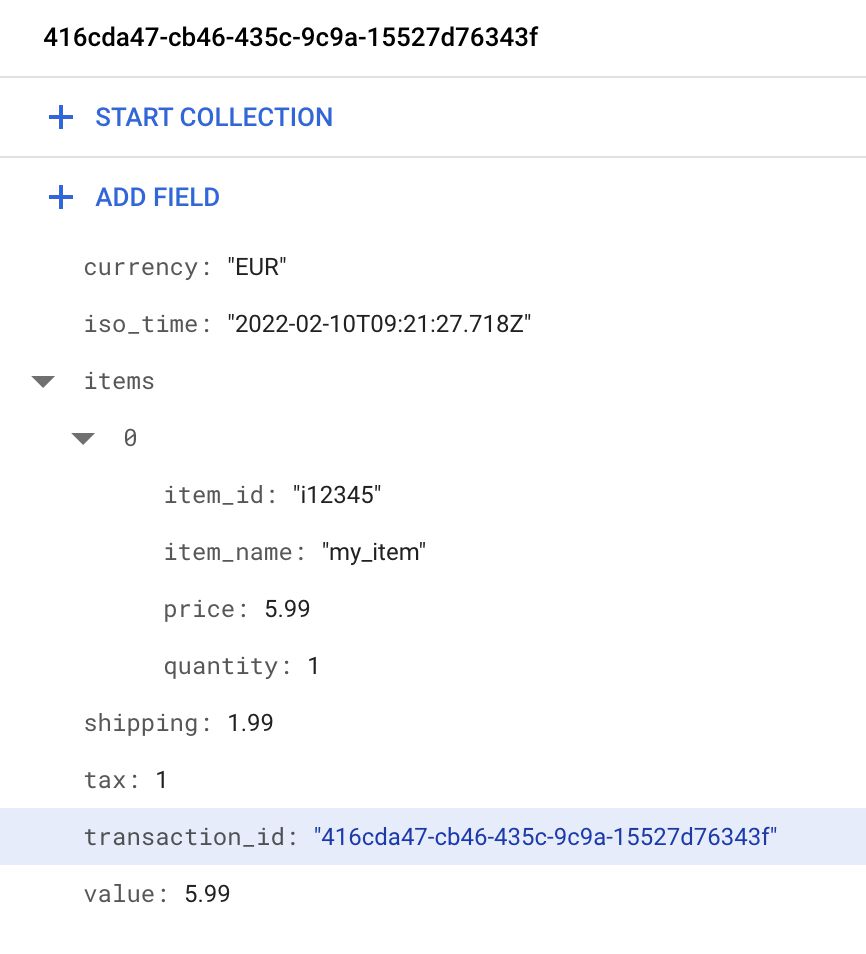{kind=link}
To fetch the transaction_id, I would set that as the Key Path. To fetch the value, I would set that. To fetch the ID of the first item, I could use items.0.item_id, and so on.
If no value is found, then the Default Value is returned if set, or undefined otherwise.
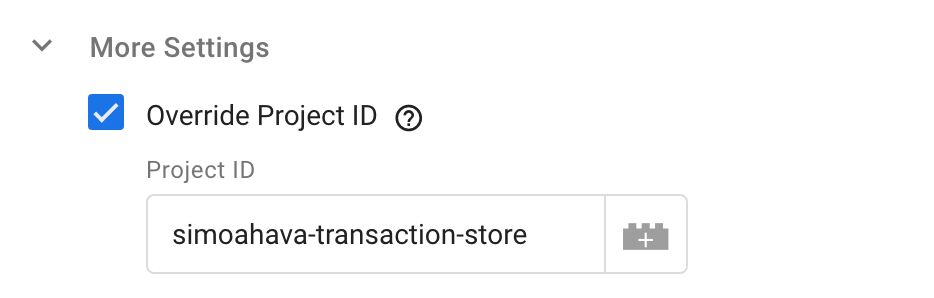
Override Project ID
By default, the variable looks for collections and documents in the same Google Cloud Project that runs the GTM server.
Note! This requires that the Project ID is set in the
GOOGLE_CLOUD_PROJECTenvironment variable of the cloud service. This is done automatically in the App Engine deployment. If you’re running Cloud Run or some other stack, you need to add the environment variable to the service or you can simply type the project ID into the Project ID field.
If you want, you can override the Project ID and provide some other Google Cloud Project ID where the collection is stored.
To do this, expand More Settings in the tag and check Override Project ID.
{kind=link}
If you provide another Project ID, you must add your GTM Server project service account to the Firestore project via IAM.
{kind=link}
If you’re running your container on App Engine, locate the App Engine default service account in your GTM Server project IAM, and add it as a new role into your Firestore project.
If your container is running on Cloud Run, use the Compute Engine default service account instead.
Grant the service account a role of Cloud Datastore User to give the GTM Server access to the other project’s Firestore.
Example walkthrough
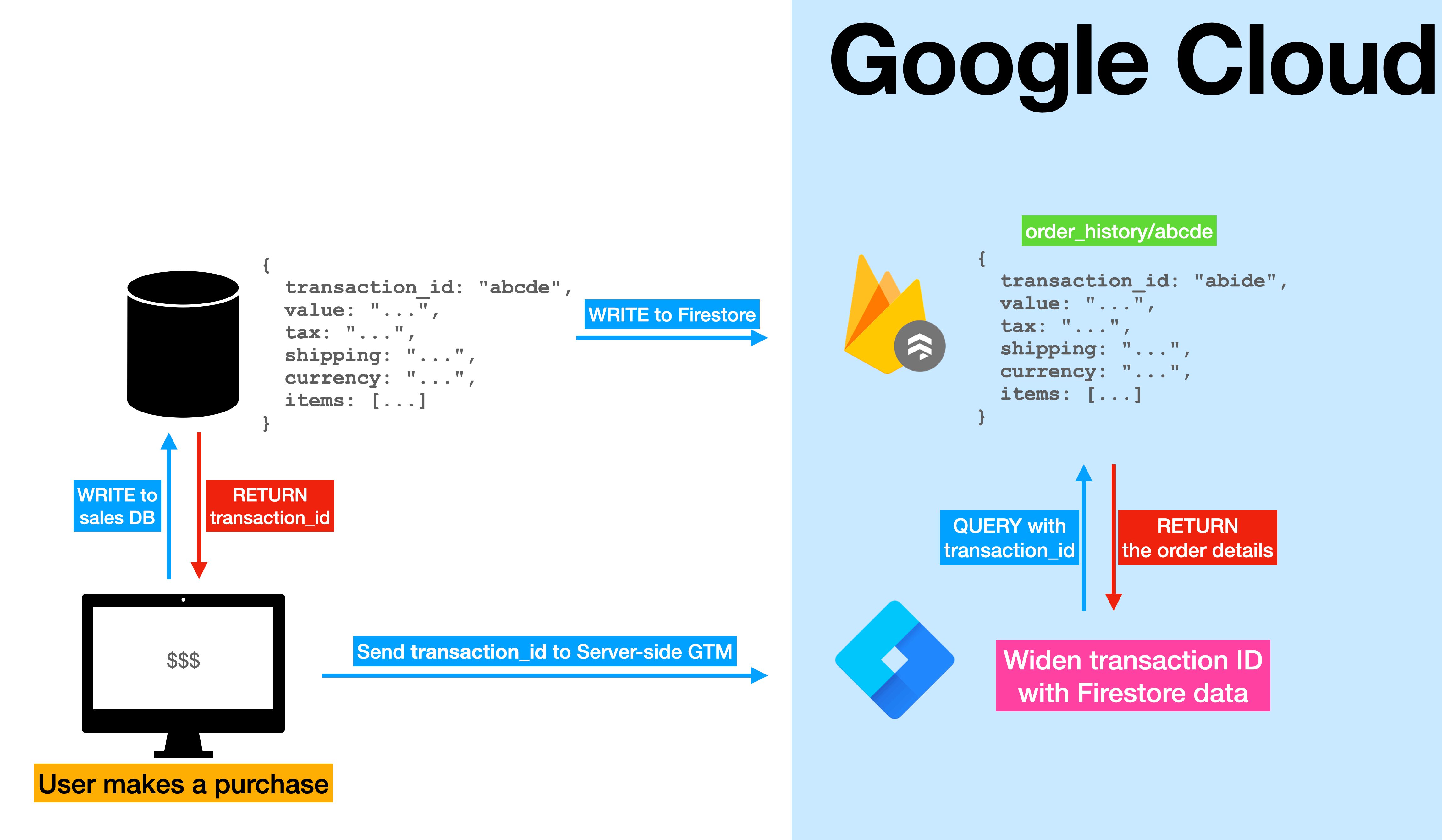
In this fictitious example, I’ll show you how you could use Firestore to widen an incoming Google Analytics 4 data stream.
{kind=link}
As you can see from the immaculately designed process flow above, there are several moving parts in this setup.
- First, the user makes a purchase on the website.
- As soon as the purchase happens, an entry is made into the local database (or service database) of the store.
- Immediately, the order details are written into a Firebase collection, too.
- The web server responds to the site that the purchase was successful, at which point the site sends a Google Analytics 4 event to the server-side Google Tag Manager endpoint, with the Transaction ID as one of the parameters.
- The server-side endpoint then takes this Transaction ID from the request and uses Firestore variables to pull the rest of the purchase information.
- These variables are then added to the server-side Google Analytics tag (and other tags that need this information), in order to complete the required parameters that a well-formed Purchase event requires.
Because this is a made-up example, I’m going to skip steps 1–3. It’s a bit of a cop-out because engineering the data flow from the sales engine to Firestore isn’t trivial to do. It has to happen immediately to avoid latency and potential race conditions, where the server container tries to query for data that doesn’t (yet) exist.
Firestore collection
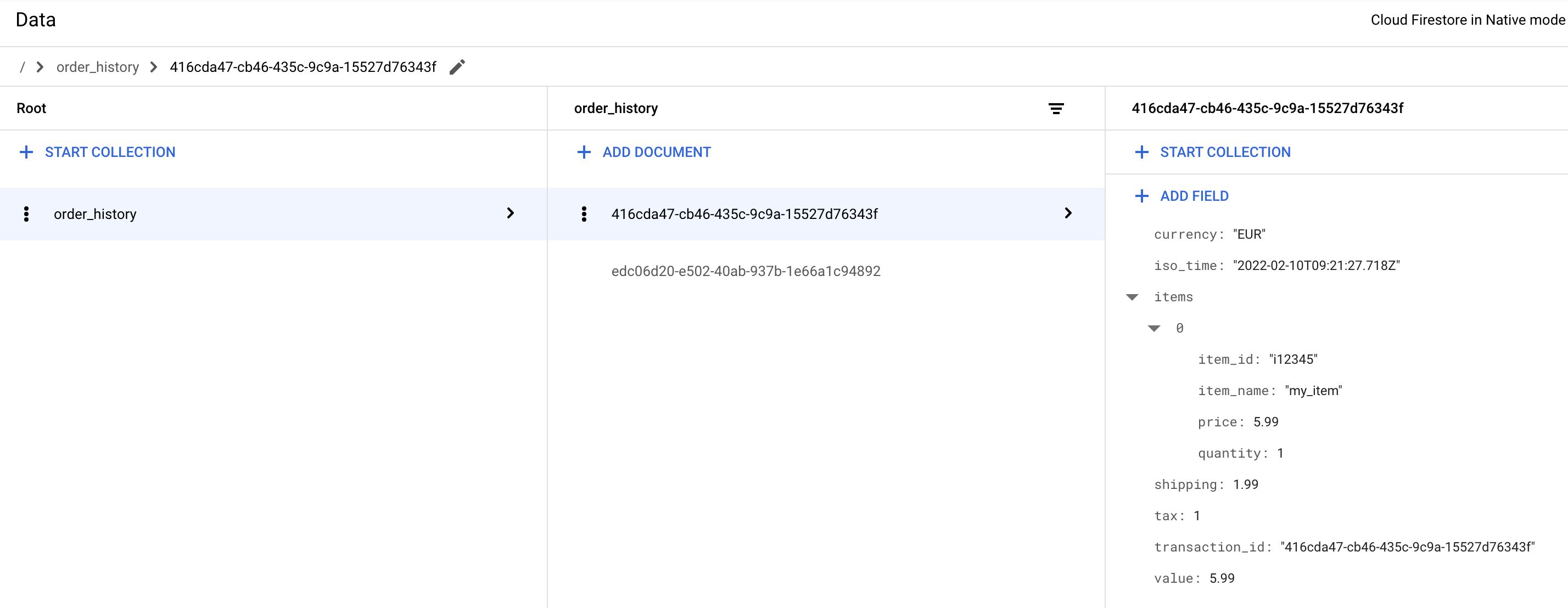
In Firestore, the collection ends up looking like this:
{kind=link}
There’s a collection called order_history, under which each transaction is its own, unique document. I’m using the Transaction ID as the name of each document to make the lookup easier.
Each transaction document has the following fields. I’ve chosen these fields and these types to require as little transformation in the Server container as possible. Thus, the fields and the values follow closely what GA4’s ecommerce schema expects.
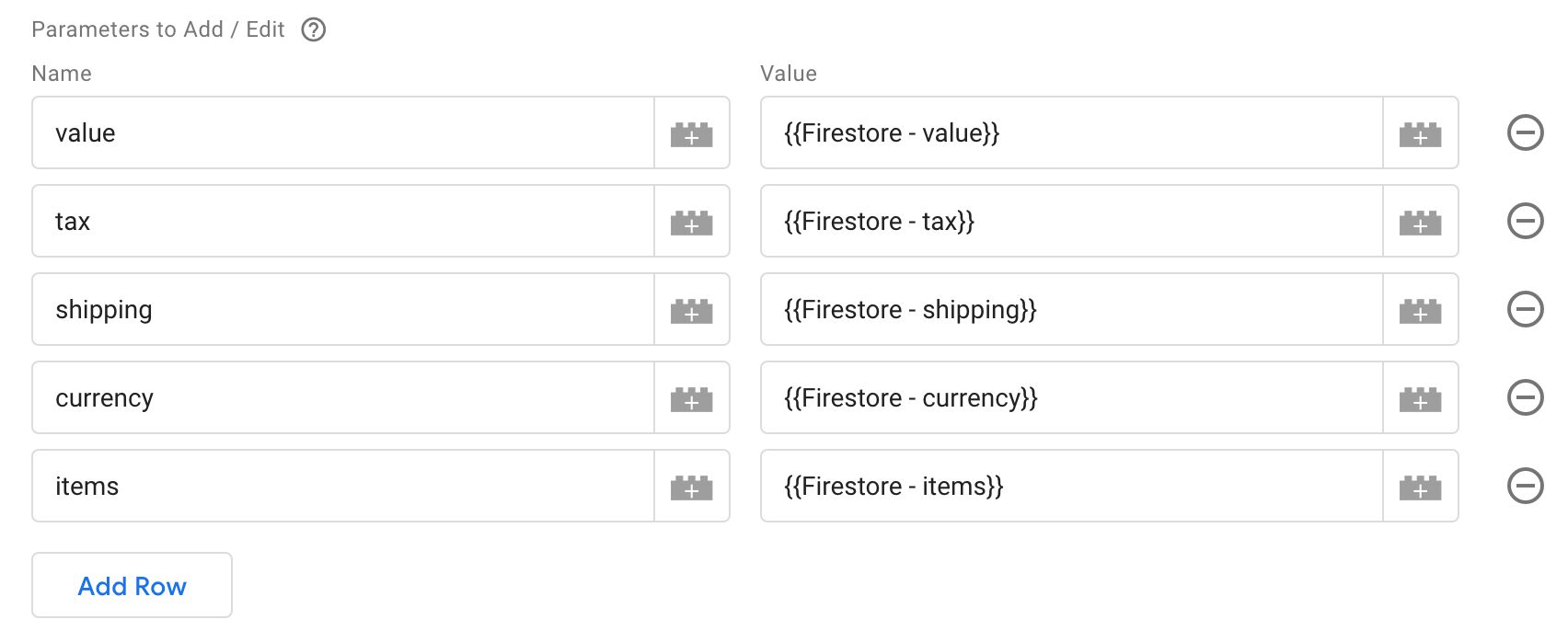
currency- the local currency of the purchase (e.g.EUR).iso_time- timestamp of when the order happened (for convenience).items- an array of all the items included in the transaction.shipping- shipping cost (e.g.1.99).tax- how much tax was paid (e.g.1.24).transaction_id- the order ID (duplicate of the document name).value- the total value of the purchase.
Server-side GTM setup
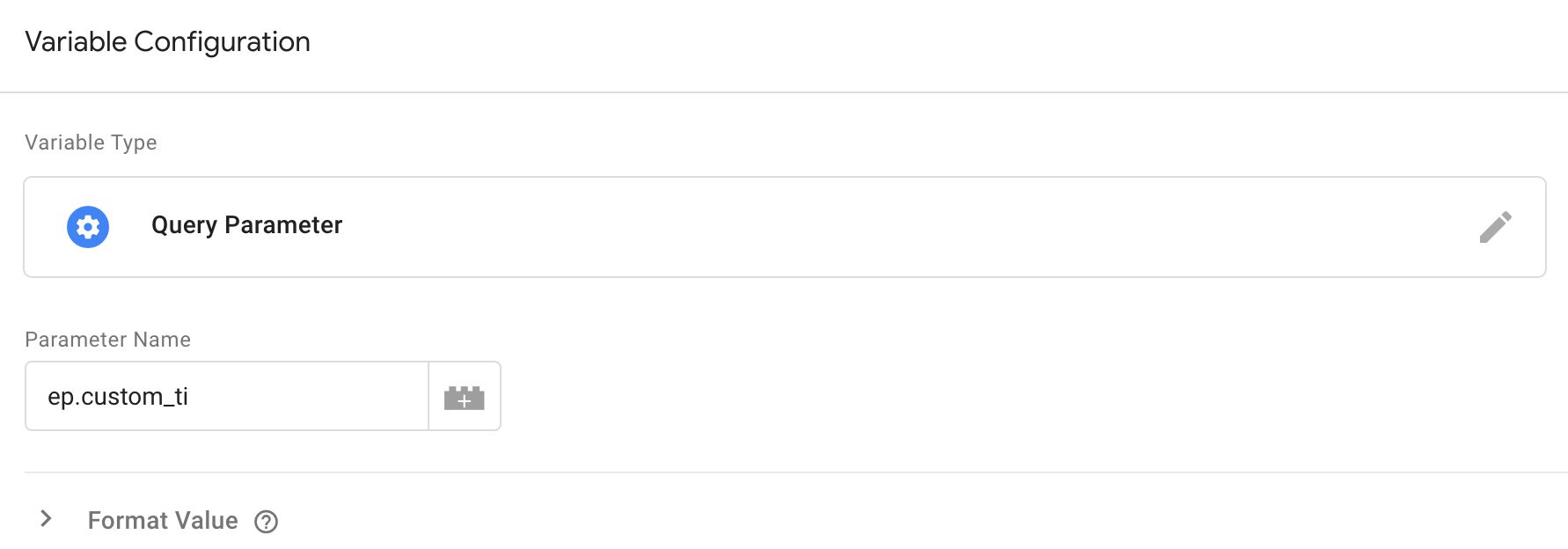
In server-side GTM, I’ve got a Google Analytics 4 event tag set to fire when the event with the Transaction ID comes in.
The Transaction ID is sent as a custom event parameter with the name custom_ti. Thus, I can create a Query Parameter variable for it like this:
{kind=link}
This variable returns the value of the &ep.custom_ti parameter in the incoming GA4 request.
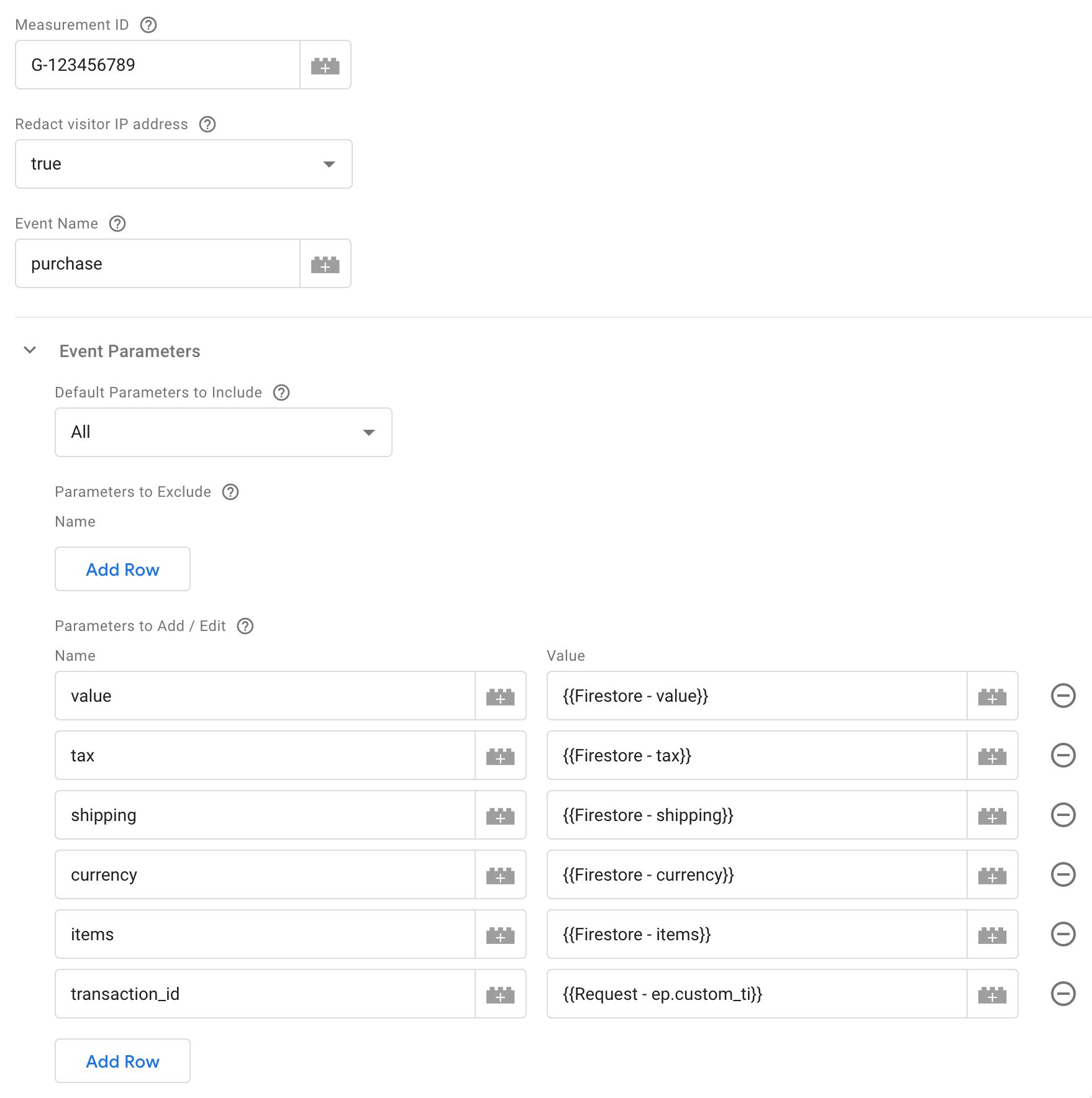
My Google Analytics 4 tag in the Server container then looks like this:
{kind=link}
Here, you can see that I hard-code the event name as purchase. Then, all the fields that GA4 expects to be included in a Purchase hit are added to the tag.
The transaction_id is set to point to the custom parameter in the incoming request, and all the other fields are Firestore variables.
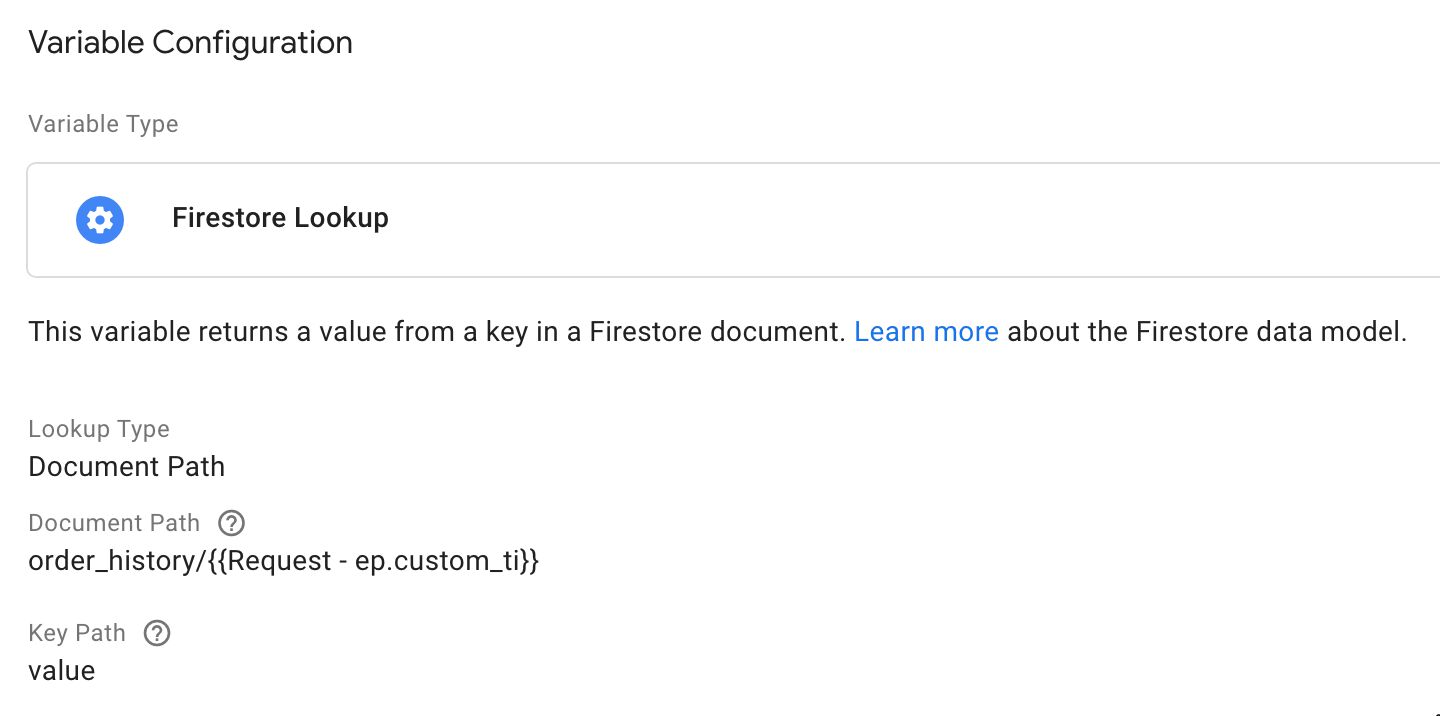
Each Firestore variable points to the relevant key in the order document. Here’s how the variables are configured:
{kind=link}
As you can see, I’m using the {{Request - ep.custom_ti}} variable (which takes the Transaction ID from the request URL) to establish the Document Path (with the order_history collection name hard-coded).
This is why I set the Transaction ID as the document name when creating the Firestore collection. I can do direct lookups rather than having to make queries.
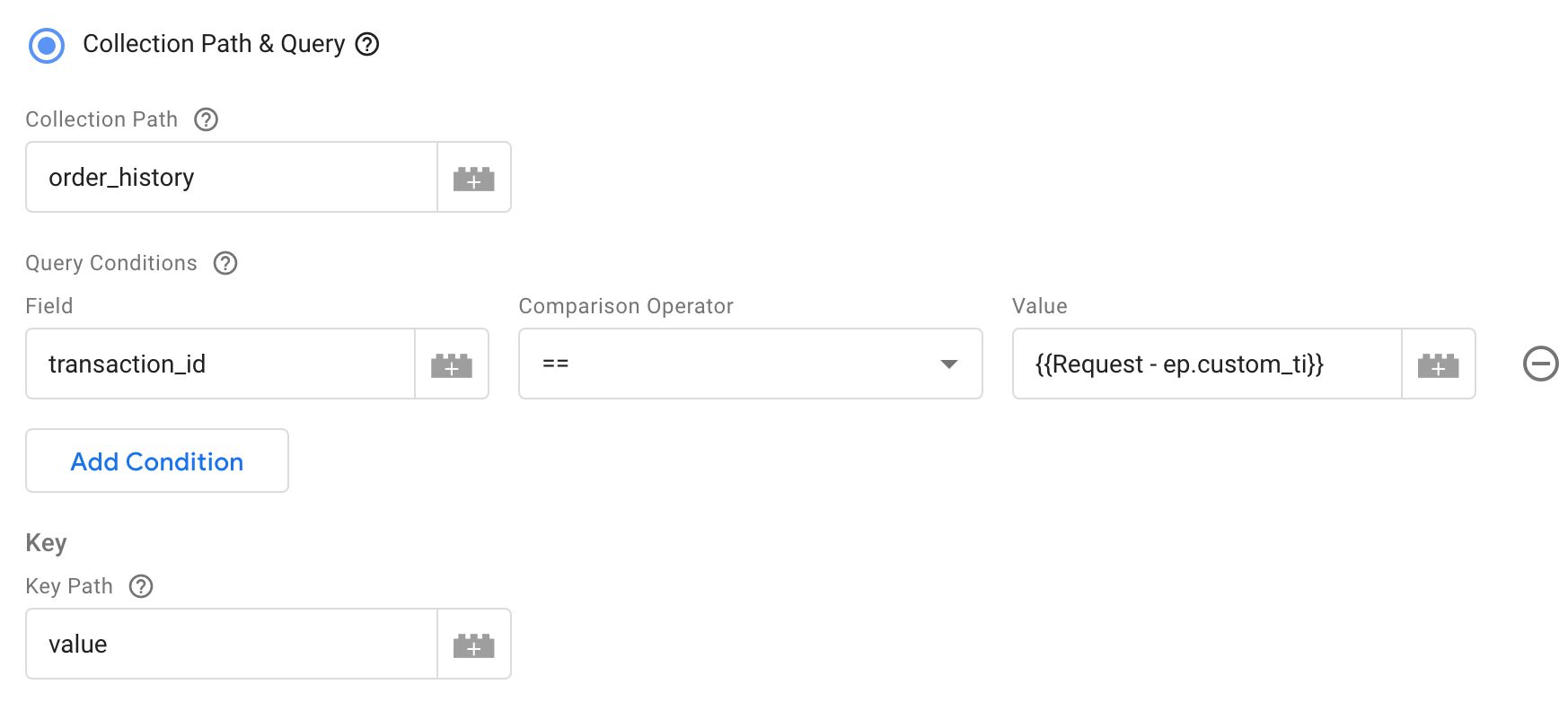
If I did want to make a query, this is how I could fetch the correct document:
{kind=link}
This would fetch the first document that has the transaction_id field with the same value as the ep.custom_ti parameter in the incoming request.
Outcome
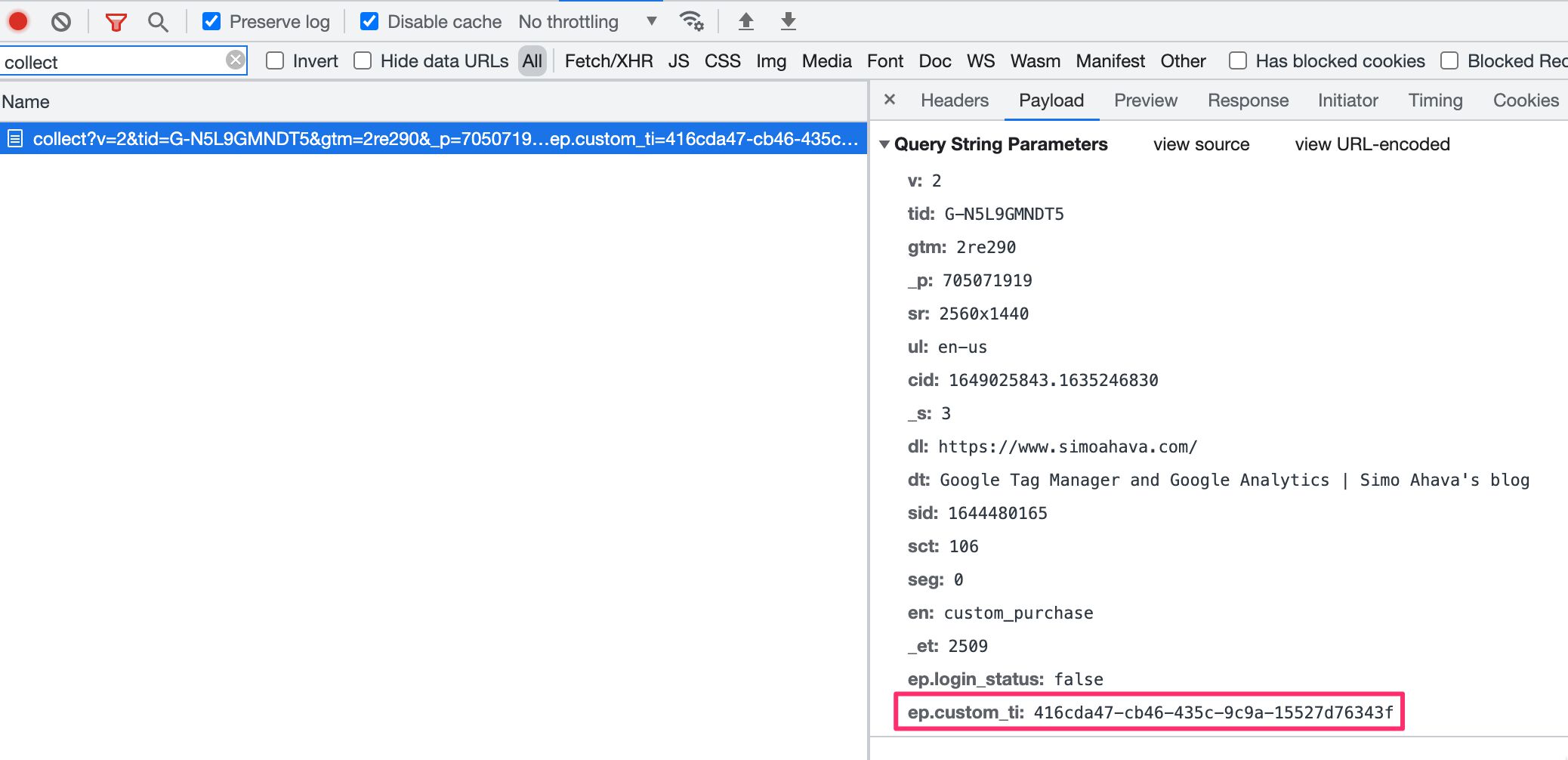
When testing this, I’ll first need to check that the incoming request looks good:
{kind=link}
Yes, there’s our ep.custom_ti parameter! The event name is custom_purchase but this is irrelevant because we hard-code it to purchase in the Server container.
Now, let’s take a look at all the outgoing network calls that the Server container makes when the incoming request is processed:
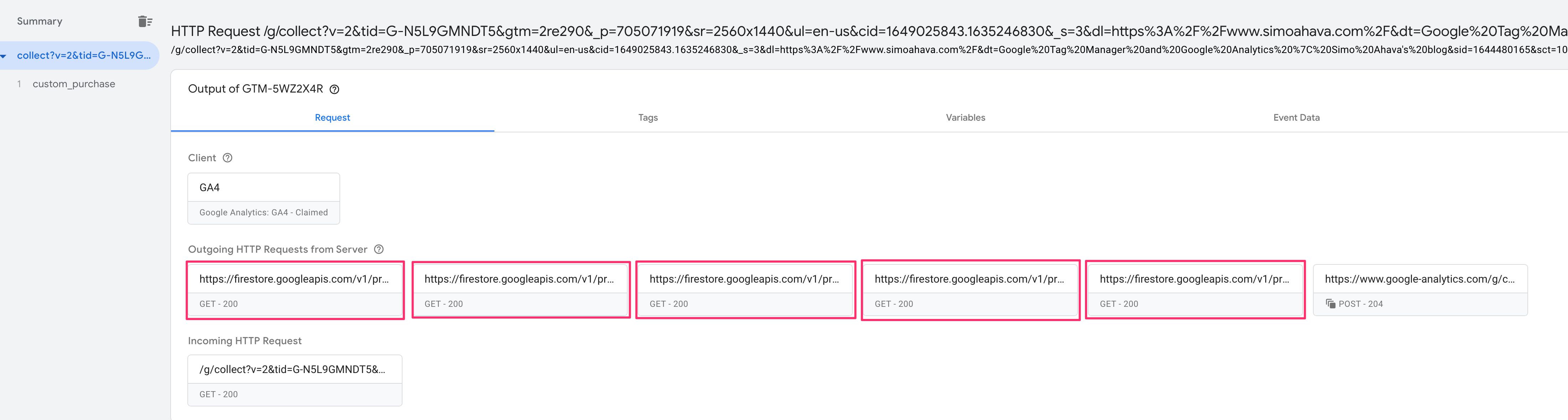{kind=link}
Uhh, that’s quite a few Firestore calls. Well, there’s one for each key that is fetched from Firestore. Luckily they all return 200 status.
I’ll then select the custom_purchase event and check what my variables return.
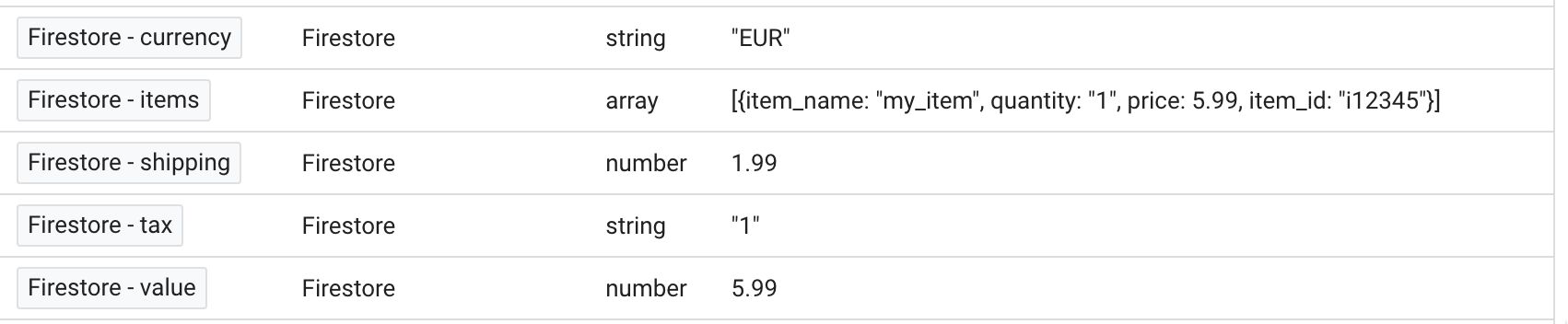{kind=link}
Looking very good! All of the variables have values, and these values match what was written into the Firebase document.
Finally, let’s see what the GA4 tag sent to Google servers.
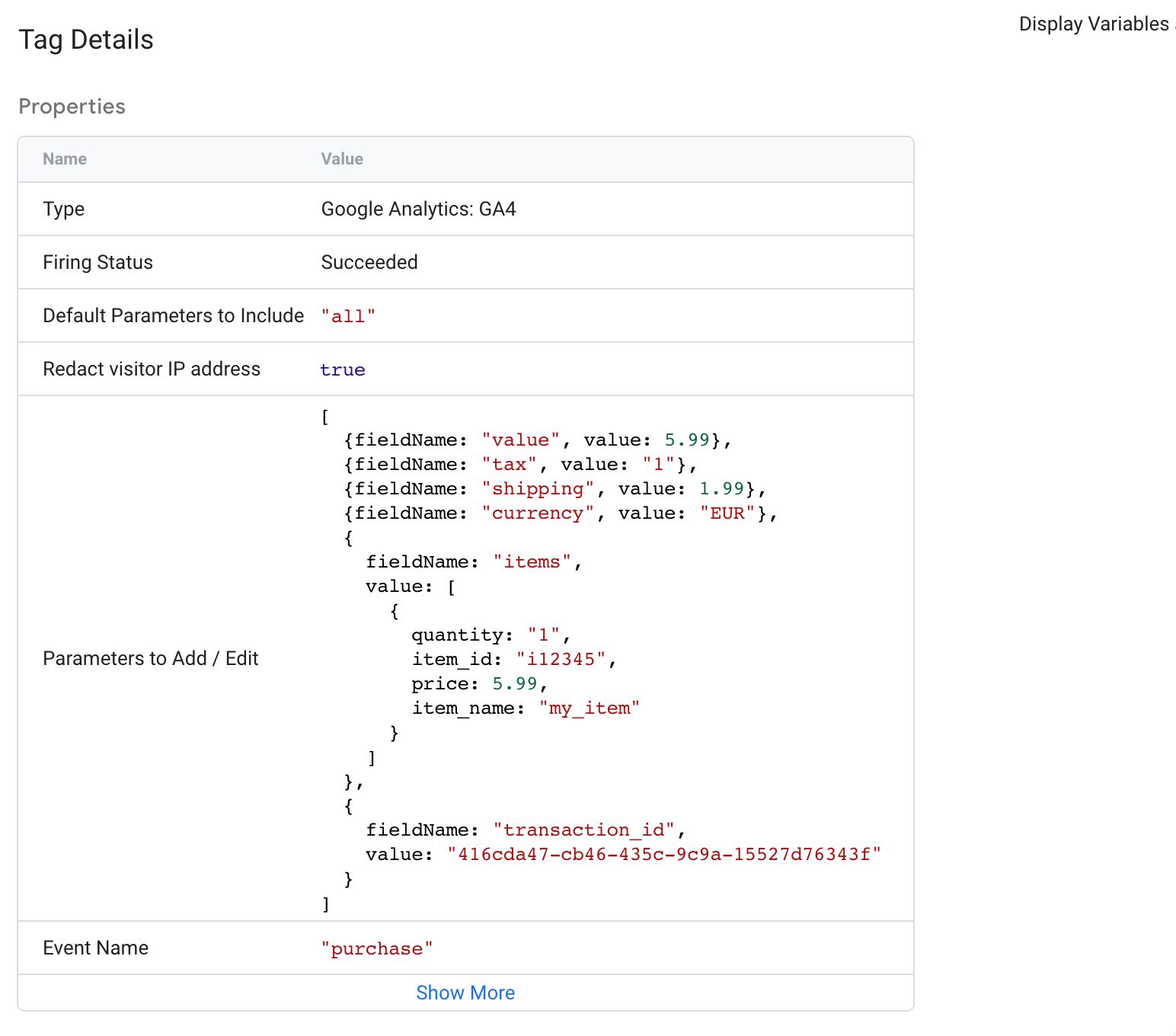{kind=link}
Yes! All the fields are set correctly. OK, let’s quickly peek at the outbound request, too.
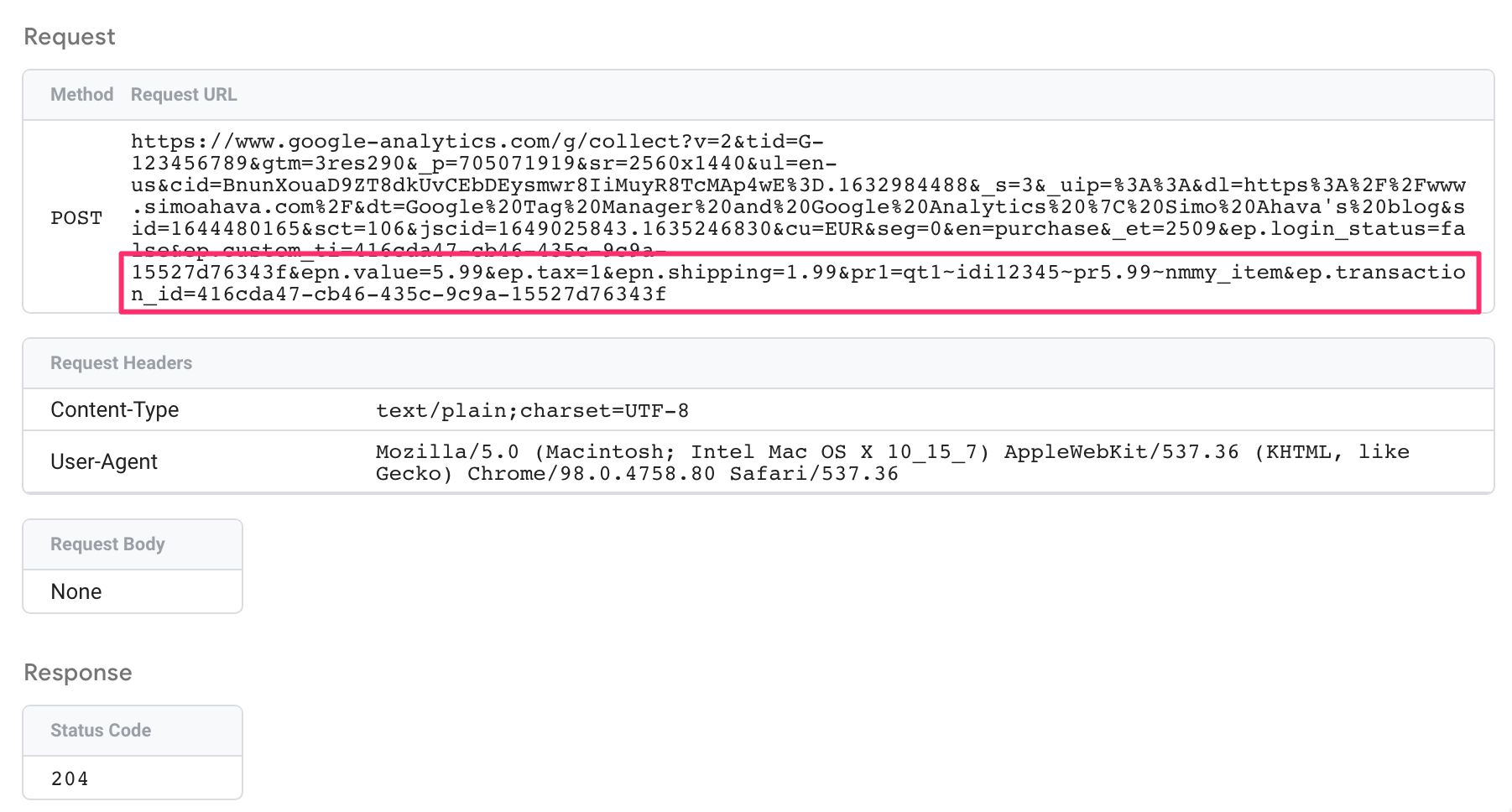{kind=link}
And there you have it. If you recall, I only sent the transaction ID to the server. It was widened with data from the Firestore document, and the final request to Google servers was formatted as a proper purchase event.
This all was done without having to create any custom Client, tag, or variable templates.
Obviously, this isn’t the most useful example, because typically you’d include the transaction data already in the client. But as an example of how data widening works, I think it’s a pretty nifty setup.
The new template APIs
In addition to the Firestore variable, a new template API, Firestore, has been released. All its methods are Promise-friendly, of course.
Firestore.read– use this to fetch a document or collection from Firestore with a direct lookup.Firestore.write- use this to write into a document in Firestore. If the document doesn’t exist, it’s automatically created in the collection.Firestore.query- use this to fetch document(s) that match the given query.Firestore.runTransaction- use this to run batched and atomic read/write operations.
As an example, here’s what a Firestore.query call would look like:
const Firestore = require('Firestore');
const queries = [['user_id', '==', 'admin'], ['country', '==', 'FI']];
return Firestore.query('users', queries, {
projectId: 'my-project',
limit: 1,
}).then((documents) => {
return documents;
});
This queries the collection users for a document (one, because limit is 1), which has the user_id key set to admin and the country key set to FI.
If successful, an array of matching documents (again, just one) is returned by the callback.
Note that for this to work in a variable, the API call itself must be returned (return Firestore.query...), as it returns a Promise that GTM’s runtime code will then handle appropriately.
runTransaction might sound confusing, but it’s a useful way of having a set of write operations immediately following a related set of read operations. This is handy if the write requires an input from the read. The atomicity refers to the fact that either all operations are a success or all operations fail. In case of failure, up to two retries are automatically done. If three total attempts fail, the API rejects the Promise with an error.
Transactions are a way of protecting your read-write setups from other, concurrent write operations. For example, while reading the data from a Firestore document, if some other process modifies this data, then the transaction automatically starts over to ensure that it runs on the most recent and up-to-date data.
Read more about these APIs here.
Summary
Firestore might be more obscure for “casual” Google Tag Manager users, at least when compared to something like Google BigQuery.
However, while BigQuery is a great data warehouse, it’s not a transactional database, as its read operations can’t handle the type of low latency and cost that a NoSQL, real-time database like Firestore can.
The opportunities for enriching data are limitless. Naturally, you need to have a plan in place for populating those Firestore documents, but for data widening purposes you could do things like…
- Build a hash table of users’ first-party identifiers to make sure that what’s stored on their device isn’t what’s sent to the vendors.
- Temporarily cache information that needs to be available to other requests in the Server container, too. This is more deterministic than what
templateDataStorageoffers. - Build a simple real-time analytics system where the Server container writes the hit stream data and a dashboard reads it.
- Build a real-time monitor to quickly address potential data collection issues.
- And of course the million different use cases for enriching data using an input key from the incoming request, similar to what we did in this article.
I’m excited at having another, extremely useful Google Cloud API to play with in the Server container.
What do you think about Firestore? Can you think of other, cool use cases for the API?